
1. Introduction▲
Les navigateurs Web sont probablement les logiciels les plus utilisûˋs. Dans cet abûˋcûˋdaire, je vais vous expliquer comment ils fonctionnent en arriû´re-plan. Nous allons voir ce qui se passe û partir du moment oû¿ vous tapez ô¨ google.com ô£ dans la barre d'adresse jusqu'û ce que vous puissiez voir la page de Google dans votre navigateur.
1-1. Les navigateurs dont nous allons parler▲
De nos jours, il y a cinq navigateurs principaux utilisûˋs - Internet Explorer, Firefox, Safari, Chrome et Opera. Je vais donner des exemples û partir des navigateurs open source - Firefox, Chrome et Safari (qui est partiellement open source). Selon les statistiques de StatCounter browser statistics, actuellement (aoû£t 2011), la part d'utilisation de Firefox, Safari et Chrome ensemble est de prû´s de 60 % (NdT pour janvier 2013, cette proportion passe û plus de 66 %). Ainsi, de nos jours, les navigateurs open source sont les plus utilisûˋs.
1-2. La fonctionnalitûˋ principale du navigateur▲
Le but principal d'un navigateur est de prûˋsenter la ressource Web que vous choisissez, en faisant la demande û partir du serveur et de l'afficher sur la fenûˆtre du navigateur. La ressource est gûˋnûˋralement un document HTML, mais peut aussi ûˆtre un PDF, une image ou un autre type. L'emplacement de la ressource est spûˋcifiûˋ par l'utilisateur û l'aide d'une URI (Uniform Resource Identifier).
La faûÏon dont le navigateur interprû´te et affiche les fichiers HTML est prûˋcisûˋe dans les spûˋcifications HTML et CSS. Ces spûˋcifications sont maintenues par le l'organisation W3C (World Wide Web Consortium), organisation des normes du Web.
Pendant des annûˋes, les navigateurs ne respectaient qu'une partie de ces spûˋcifications et dûˋveloppaient leurs propres extensions. Cela a causûˋ de graves problû´mes de compatibilitûˋ pour les concepteurs Web. Aujourd'hui, la plupart des navigateurs sont plus ou moins conformes û ces spûˋcifications.
Les interfaces des navigateurs ont beaucoup d'ûˋlûˋments en commun. On y trouve :
- une barre d'adresse pour insûˋrer l'URL ;
- des boutons ô¨ Prûˋcûˋdent ô£ et ô¨ Suivant ô£ ;
- des options de marque-pages ;
- des boutons d'actualisation et d'arrûˆt pour se rafraûÛchir et arrûˆter le chargement des documents courants ;
- un bouton ô¨ Accueil ô£ qui vous ramû´ne û votre page d'accueil.
Curieusement, l'interface du navigateur n'est pas spûˋcifiûˋe dans une spûˋcification formelle, il s'agit simplement de bonnes pratiques faûÏonnûˋes au fil des annûˋes d'expûˋrience et par l'imitation des autres navigateurs. La spûˋcification HTML5 ne dûˋfinit pas les ûˋlûˋments d'interface que doit avoir un navigateur, mais ûˋnumû´re certains ûˋlûˋments communs. Parmi celles-ci, la barre d'adresse, la barre d'ûˋtat et la barre d'outils. Il y a bien sû£r les caractûˋristiques propres û un navigateur spûˋcifique comme le gestionnaire de tûˋlûˋchargements de Firefox.
1-3. La structure haut niveau d'un navigateur▲
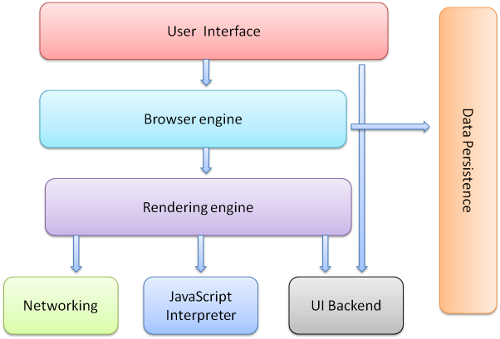
Les principaux composants (voir ) d'un navigateur sont :
- L'interface utilisateur - ce qui inclut la barre d'adresse, les boutons avant et arriû´re, le menu de marque-page, etc. En fait, chacune des parties affichûˋes par le navigateur exceptûˋ la fenûˆtre principale dans laquelle vous voyez la page demandûˋe ;
- Le moteur du navigateur - contrûÇle les actions entre l'interface et le moteur de rendu ;
- Le moteur de rendu - responsable de l'affichage du contenu demandûˋ. Par exemple, si le contenu demandûˋ est au format HTML, il est chargûˋ d'analyser le code HTML et CSS et d'afficher le contenu analysûˋ û l'ûˋcran ;
- Le rûˋseau - utilisûˋ pour les appels rûˋseau, comme les requûˆtes HTTP. Il possû´de une interface indûˋpendante de la plateforme et en dessous des implûˋmentations pour chaque plateforme ;
- L'interface utilisateur - utilisûˋe pour dessiner des widgets de base comme des listes dûˋroulantes et des fenûˆtres. Le navigateur expose une interface gûˋnûˋrique qui n'est pas spûˋcifique û la plateforme. En dessous, il utilise l'interface utilisateur du systû´me d'exploitation ;
- L'interprûˋteur JavaScript - utilisûˋ pour analyser et exûˋcuter le code JavaScript ;
- Le stockage de donnûˋes - il s'agit d'une couche de persistance. Le navigateur doit enregistrer toutes sortes de donnûˋes sur le disque dur, par exemple, des cookies. La nouvelle spûˋcification HTML (HTML5) dûˋfinit le terme ô¨ base de donnûˋes Web ô£, qui est un systû´me complet (bien que lûˋger) de base de donnûˋes dans le navigateur.
Il est important de noter que Chrome, contrairement û la plupart des navigateurs, crûˋe plusieurs instances du moteur de rendu - une pour chaque onglet. Chaque onglet est un processus distinct.
2. Le moteur de rendu▲
La responsabilitûˋ du moteur de rendu est importanteãÎ Le rendu, c'est l'affichage des contenus demandûˋs sur l'ûˋcran du navigateur.
Par dûˋfaut, le moteur de rendu peut afficher des documents HTML, XML et des images. Il peut afficher d'autres types avec un plug-in (ou extension de navigateur), par exemple, PDF s'affiche en utilisant un plug-in de visualisation de PDF. Cependant, dans ce chapitre, nous nous concentrerons sur le cas d'utilisation principal : affichage de HTML et d'images qui sont formatûˋs û l'aide de CSS.
2-1. Les moteurs de rendu▲
Nos navigateurs de rûˋfûˋrences Firefox, Chrome et Safari sont construits sur deux moteurs de rendu. Firefox utilise Gecko un moteur ô¨ fait maison ô£ de Mozilla. Safari et Chrome utilisent Webkit.
WebKit est un moteur de rendu Open Source qui a commencûˋ comme un moteur de plateforme Linux et a ûˋtûˋ modifiûˋ par Apple pour soutenir Mac et Windows. Voir webkit.org pour plus de dûˋtails.
2-2. Le flux principal▲
Le moteur de rendu commencera û obtenir le contenu du document demandûˋ mis en rûˋseau. Ce sera gûˋnûˋralement effectuûˋ en morceaux de 8 K.
Aprû´s c'est le flux de base du moteur de rendu :

Le moteur de rendu commencera û faire l'analyse du document HTML et activera les mots-clûˋs aux néuds de dans un arbre appelûˋ ô¨ arbre de contenu ô£. Il analysera les donnûˋes de style, û la fois dans les fichiers CSS externes et les ûˋlûˋments de style. L'information de style ainsi que des instructions visuelles dans le code HTML seront utilisûˋes pour crûˋer un autre arbre : ô¨ ô£.
L'arbre de rendu contient des rectangles avec des attributs visuels comme les couleurs et les dimensions. Les rectangles sont dans le bon ordre pour ûˆtre affichûˋs sur l'ûˋcran.
Aprû´s la construction de l'arbre de rendu, il passe par un processus de ô¨ ô£. Ceci signifie de donner les coordonnûˋes exactes oû¿ il devrait apparaûÛtre sur l'ûˋcran. L'ûˋtape suivante : l'arbre de rendu sera traversûˋ et chaque néud sera dessinûˋ en utilisant la couche d'arriû´re-plan de l'interface utilisateur.
Il est important de comprendre que c'est un processus graduel. Pour une meilleure expûˋrience utilisateur, le moteur de rendu essayera d'afficher le contenu sur l'ûˋcran dû´s que possible. Il n'attendra pas que tout le code HTML soit analysûˋ avant de commencer û prûˋsenter l'arbre de rendu. Les parties du contenu seront analysûˋes et affichûˋes, tandis que le processus se poursuit avec le reste de la page qui continue û arriver du rûˋseau.
2-3. Exemples des flux principaux▲
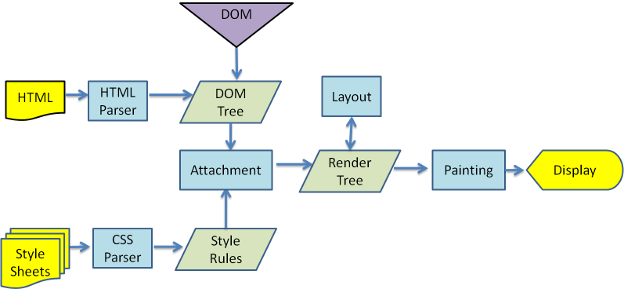
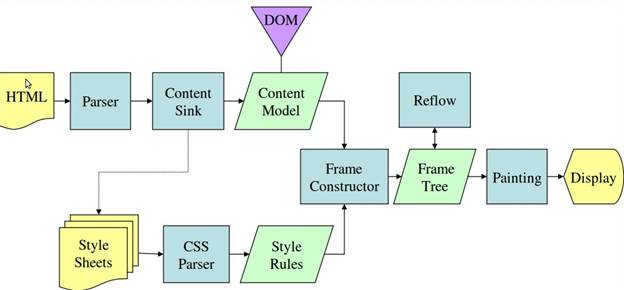
û partir des figures 3 et 4, vous pouvez voir que, bien que Webkit et Gecko utilisent une terminologie lûˋgû´rement diffûˋrente, le flux est essentiellement le mûˆme.
Gecko appelle l'arbre des ûˋlûˋments formatûˋs visuellement un ô¨ Frame tree ô£ (arbre de vue). Chaque ûˋlûˋment est un cadre. Webkit utilise le terme ô¨ arbre de rendu ô£ et il se compose de ô¨ Render Objects ô£ (objets de rendu). Webkit utilise le terme ô¨ layout ô£ (prûˋsentation) pour le placement des ûˋlûˋments, pendant que le Gecko l'appelle ô¨ Reflow ô£ (rûˋ-ûˋcoulement ). ô¨ Attachment ô£ (attachement) est le terme de Webkit pour relier les néuds de DOM et les informations visuelles afin de crûˋer l'arbre de rendu. Une diffûˋrence non sûˋmantique mineure est que Gecko a une couche supplûˋmentaire entre le HTML et l'arbre DOM. Il est appelûˋ ô¨ content sink ô£ (lavabo de contenu) et est une usine pour faire des ûˋlûˋments DOM. Nous parlerons de chaque partie du flux.
3. Analyse et construction de l'arbre DOM▲
3-1. L'analyse - gûˋnûˋralitûˋs▲
Comme l'analyse est un processus trû´s important dans le moteur de rendu, nous irons un peu plus dans les dûˋtails. CommenûÏons par une petite introduction sur l'analyse.
Analyser un document signifie le traduire en une structure qui fait sens - quelque chose que le code peut comprendre et utiliser. Le rûˋsultat de l'analyse est en gûˋnûˋral un arbre de néuds qui reprûˋsente la structure du document. Il est appelûˋ un arbre d'analyse ou un arbre syntaxique.
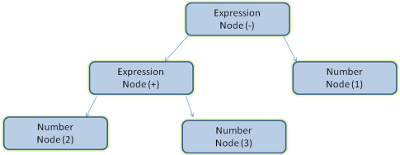
Exemple - l'analyse de l'expression 2 + 3 - 1 pourrait retourner cet arbre :
3-1-1. Les grammaires▲
L'analyse est basûˋe sur les rû´gles de syntaxe auxquelles le document obûˋit - la langue ou le format dans lequel il a ûˋtûˋ ûˋcrit. Chaque format que vous analysez doit avoir une grammaire dûˋterministe constituûˋe d'un vocabulaire et de rû´gles de syntaxe. C'est ce que l'on appelle une grammaire sans contexte. Les langues humaines n'en sont pas et ne peuvent donc pas ûˆtre analysûˋes avec des techniques d'analyse classiques.
3-1-2. La combinaison Parser - Lexer▲
L'analyse peut ûˆtre sûˋparûˋe en deux processus - l'analyse lexicale et l'analyse syntaxique.
L'analyse lexicale est le processus de sûˋparation de l'entrûˋe en mots-clûˋs. Les mots-clûˋs sont le vocabulaire de la langue - la collection de blocs de construction valides. Pour un langage humain, il se compose de tous les mots qui apparaissent dans le dictionnaire de cette langue.
L'analyse syntaxique est l'application des rû´gles de la syntaxe du langage.
Les analyseurs, gûˋnûˋralement, divisent le travail entre les deux ûˋlûˋments - l'analyseur lexical (appelûˋ lexer ou tokenizer en langue anglaise) qui est responsable de l'extraction des mots-clûˋs depuis l'entrûˋe et l'analyseur syntaxique qui est responsable de la construction de l'arbre syntaxique par l'analyse de la structure du document selon les rû´gles de syntaxe du langage. L'analyseur lexical sait comment supprimer des caractû´res non pertinents tels que les espaces et des sauts de ligne.
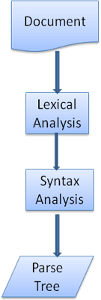
Le processus d'analyse est itûˋratif. L'analyseur syntaxique demande gûˋnûˋralement û l'analyseur lexical le prochain mot-clûˋ et essaye de faire correspondre ce mot-clûˋ avec l'une des rû´gles de syntaxe. Si une rû´gle est trouvûˋe, un néud correspondant au mot-clûˋ sera ajoutûˋ û l'arbre d'analyse et l'analyseur syntaxique demandera un autre mot-clûˋ.
Si aucune rû´gle ne correspond, l'analyseur va stocker le mot-clûˋ en interne et continuer û demander des mots-clûˋs jusqu'û ce qu'une rû´gle de correspondance avec les mots-clûˋs stockûˋs en interne soit trouvûˋe. Si aucune rû´gle n'est trouvûˋe, alors l'analyseur dûˋclenche une exception. Cela signifie que le document n'est pas valide et qu'il contient des erreurs de syntaxe.
3-1-3. La traduction▲
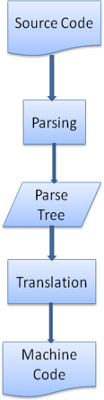
Souvent, l'arbre d'analyse syntaxique n'est pas le produit final. L'analyse est souvent employûˋe en traduction - la transformation du document d'entrûˋe en un autre format. Un exemple est la compilation. Le compilateur qui compile un code source en code machine analyse d'abord le code avec un arbre d'analyse et traduit ensuite cet arbre dans un document code machine.
3-1-4. Exemple d'analyse▲
Dans la figure 5, nous avons construit un arbre d'analyse û partir d'une expression mathûˋmatique. Essayons de dûˋfinir un langage mathûˋmatique simple et de voir le processus d'analyse.
Vocabulaire : notre langage peut inclure des nombres entiers ainsi que les signes plus et moins.
Syntaxe :
- Les blocs de construction sont des expressions, des termes et des opûˋrations ;
- Notre langage peut comporter un nombre quelconque d'expressions ;
- Une expression est dûˋfinie comme un ô¨ terme ô£ suivi d'une ô¨ opûˋration ô£ suivie par un autre terme ;
- Une opûˋration est un signe plus ou un signe moins ;
- Un terme est un entier ou une expression.
Analysons l'entrûˋe 2 + 3 - 1.
La premiû´re chaûÛne qui correspond û une rû´gle est 2 et conformûˋment û la rû´gle Nô¯ 5, c'est un terme. La deuxiû´me correspondance est 2 + 3 cela correspond û la troisiû´me rû´gle - un terme suivi d'une opûˋration suivie par un autre terme. La prochaine correspondance ne sera atteinte qu'û la fin de l'entrûˋe. 2 + 3 - 1 est une expression parce que nous savons dûˋjû que 2 +3 est un terme et que nous avons un terme suivi par une opûˋration suivie par un autre terme. 2 + + ne correspond û aucune rû´gle et n'est donc pas une entrûˋe valide.
3-1-5. Dûˋfinitions formelles du vocabulaire et de la syntaxe▲
Le vocabulaire est en gûˋnûˋral exprimûˋ par des expressions rûˋguliû´res.
Par exemple, notre langage sera dûˋfini comme :
2.
3.
INTEGER :0|[1-9][0-9]*
PLUS : +
MINUS: -
Comme vous le voyez, les nombres sont dûˋfinis par une expression rûˋguliû´re.
La syntaxe est gûˋnûˋralement dûˋfinie dans un format nommûˋ BNF. Notre langage sera dûˋfini comme cela :
2.
3.
expression := term operation term
operation := PLUS | MINUS
term := INTEGER | expression
Nous avons dit qu'un langage peut ûˆtre analysûˋ par un analyseur normal si sa grammaire est une grammaire sans contexte. La dûˋfinition intuitive d'une grammaire sans contexte est une grammaire qui peut entiû´rement ûˆtre exprimûˋe en format BNF. Pour une dûˋfinition plus formelle voir l'article Wikipûˋdiasur les grammaires sans contexte.
3-1-6. Les types d'analyseurs▲
Il y a deux types d'analyseurs - les analyseurs de haut en bas (top down) et les analyseurs de bas en haut (bottom up). Une explication intuitive est que les analyseurs de haut en bas voient la structure de la syntaxe de haut niveau et tentent de faire correspondre l'entrûˋe û l'une des rû´gles. Les analyseurs de bas en haut commencent avec l'entrûˋe et la transforment peu û peu en rû´gles de syntaxe, û partir des rû´gles de bas niveau jusqu'û ce que les rû´gles de haut niveau soient remplies.
Voyons comment ces deux types d'analyseurs vont analyser notre exemple.
Un analyseur de haut en bas commencera û partir de la rû´gle de niveau supûˋrieur - il identifiera 2 + 3 comme une expression. Il identifiera alors 2 + 3 - 1 comme une expression (le processus d'identification de l'expression change pour correspondre avec les autres rû´gles, mais le point de dûˋpart est la rû´gle de plus haut niveau).
Un analyseur de bas en haut va lire l'entrûˋe jusqu'û ce qu'une rû´gle corresponde et il remplacera alors l'entrûˋe correspondant û la rû´gle. Et ainsi de suite jusqu'û la fin de l'entrûˋe. L'expression partiellement identifiûˋe est placûˋe sur la pile analyseurs.
| Pile | Entrûˋe |
| 2 + 3 - 1 | |
| terme | + 3 - 1 |
| terme opûˋration | 3 - 1 |
| expression | - 1 |
| expression opûˋration | 1 |
| expression |
Ce type d'analyseur de bas en haut est appelûˋ analyseur û dûˋcalage-rûˋduction, parce que l'entrûˋe est dûˋcalûˋe vers la droite (imaginez un pointeur pointant d'abord sur le dûˋbut de l'entrûˋe puis se dûˋplaûÏant vers la droite) et est progressivement rûˋduite û des rû´gles de syntaxe.
3-1-7. Gûˋnûˋrer des analyseurs automatiquement▲
Il existe des outils qui permettent de gûˋnûˋrer un analyseur syntaxique pour vous. Ils sont appelûˋs gûˋnûˋrateurs d'analyseurs. Vous leur fournissez la grammaire de la langue, son vocabulaire et la syntaxe de ses rû´gles, et ils gûˋnû´rent un analyseur. La crûˋation d'un analyseur nûˋcessite une connaissance approfondie de l'analyse et comme il n'est pas facile de crûˋer û la main un analyseur optimisûˋ, ces gûˋnûˋrateurs d'analyseurs sont donc trû´s utiles.
Webkit utilise deux gûˋnûˋrateurs d'analyseur bien connus - Flex pour crûˋer l'analyseur lexical et Bison pour la crûˋation de l'analyseur syntaxique (vous pourrez aussi les rencontrer avec les termes Lex et Yacc). L'entrûˋe de Flex est un fichier contenant la dûˋfinition des expressions rûˋguliû´res des mots-clûˋs. L'entrûˋe de Bison est constituûˋe par les rû´gles de syntaxe du langage au format BNF.
3-2. L'analyseur HTML▲
Le rûÇle de l'analyseur HTML est d'analyser les balises HTML et de crûˋer un arbre d'analyse.
3-2-1. La dûˋfinition de la grammaire HTML▲
Le vocabulaire et la syntaxe du langage HTML sont dûˋfinis dans des spûˋcifications crûˋûˋes par l'organisation W3C. La version actuelle est HTML4 et le travail sur le HTML5 est en cours.
3-2-2. Ce n'est pas une grammaire sans contexte▲
Comme nous l'avons vu dans l'introduction sur l'analyse, la syntaxe grammaticale peut ûˆtre dûˋfinie de maniû´re formelle en utilisant des formats tels que la BNF.
Malheureusement, la notion d'analyseur conventionnel ne s'applique pas au format HTML (je n'en ai pas parlûˋ juste pour le plaisir, ils seront utilisûˋs lors de l'analyse CSS et JavaScript). HTML ne peut pas ûˆtre dûˋfini facilement avec la grammaire sans contexte dont ont besoin les analyseurs.
Il existe un document officiel pour dûˋfinir HTML, une DTD (Document Type Definition), mais ce n'est pas une grammaire sans contexte.
Cela semble ûˋtrange û premiû´re vue ; HTML ûˋtant assez proche de XML. Il existe beaucoup d'analyseurs XML disponibles. Il y a une diffûˋrence entre XML et HTML - XHTML, alors quelle est cette diffûˋrence ?
La diffûˋrence est que l'approche HTML est plus ô¨ clûˋmente ô£, elle vous permet d'omettre certaines balises qui sont ajoutûˋes implicitement, ou encore le dûˋbut ou la fin de la balise, etc. Dans l'ensemble c'est une syntaxe ô¨ souple ô£, par opposition û la syntaxe ô¨ stricte ô£ et ô¨ exigeante ô£ de XML.
Apparemment, cette petite diffûˋrence fait un monde de diffûˋrence. D'une part, c'est la raison principale pour laquelle HTML est si populaire, il pardonne vos erreurs et facilite la vie aux auteurs Web. D'autre part, il est difficile d'ûˋcrire une grammaire formelle. Donc, pour rûˋsumer, HTML ne peut pas ûˆtre analysûˋ facilement, en tout cas pas par des analyseurs conventionnels, puisque sa grammaire n'est pas une grammaire sans contexte, ni par des analyseurs XML.
3-2-3. La DTD HTML▲
La dûˋfinition HTML est dans un format DTD. Ce format est utilisûˋ pour dûˋfinir les langues de la famille SGML. Le format contient les dûˋfinitions de tous les ûˋlûˋments autorisûˋs, leurs attributs et leur hiûˋrarchie. Comme nous l'avons vu prûˋcûˋdemment, la DTD HTML ne constitue pas une grammaire sans contexte.
Il existe quelques variantes de DTD. Le mode strict se conforme uniquement û la norme, mais d'autres modes supportent les formes utilisûˋes par les navigateurs dans le passûˋ. Le but est la rûˋtrocompatibilitûˋ avec les anciens contenus. La DTD stricte actuelle se trouve ici : www.w3.org/TR/html4/strict.dtd.
3-2-4. Le DOM▲
L'arbre de sortie, ô¨ l'arbre syntaxique ô£, est constituûˋ de néuds ûˋlûˋments et attributs DOM. DOM est l'acronyme de ô¨ Document Object Model ô£. Il s'agit de la reprûˋsentation ô¨ objet ô£ du document HTML ainsi que l'interface des ûˋlûˋments HTML avec le monde extûˋrieur comme JavaScript.
La racine de l'arbre est l'objet ô¨ document ô£.
Le DOM possû´de une relation quasiment un-û -un avec le balisage. Par exemple, ce code :
Se traduirait par l'arbre DOM suivant :
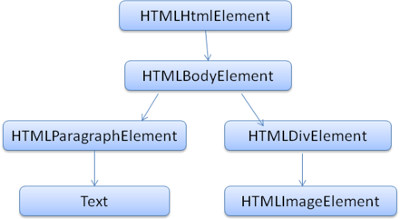
Comme pour HTML, DOM est spûˋcifiûˋ par l'organisation W3C , voir www.w3.org/DOM/DOMTR. C'est une spûˋcification gûˋnûˋrique pour la manipulation de documents. Un document spûˋcifique dûˋcrit les ûˋlûˋments propres û HTML. La dûˋfinition HTML peut ûˆtre trouvûˋe ici : www.w3.org/TR/2003/REC-DOM-Level-2-HTML-20030109/idl-definitions.html.
Quand je dis que l'arbre contient des néuds DOM, je veux dire que l'arbre est constituûˋ d'ûˋlûˋments qui mettent en éuvre l'une des interfaces DOM. Les navigateurs utilisent des implûˋmentations concrû´tes qui ont d'autres attributs utilisûˋs par le navigateur en interne.
3-2-5. L'algorithme d'analyse▲
Comme nous l'avons vu auparavant, le langage HTML ne peut pas ûˆtre analysûˋ en utilisant des analyseurs de bas en haut ou de haut en bas.
Les raisons sont :
- La nature indulgente du langage ;
- Le fait que les navigateurs ont une tolûˋrance traditionnelle aux erreurs pour supporter les cas bien connus de HTML non valide ;
- Le processus d'analyse est rûˋentrant. Habituellement, la source ne change pas pendant l'analyse, mais en HTML, des balises de script contenant document.write peuvent ajouter des entrûˋes supplûˋmentaires, de sorte que le processus d'analyse modifie en fait l'entrûˋe.
Incapables d'utiliser les techniques traditionnelles d'analyse, les navigateurs doivent utiliser des analyseurs personnalisûˋs pour lire le HTML.
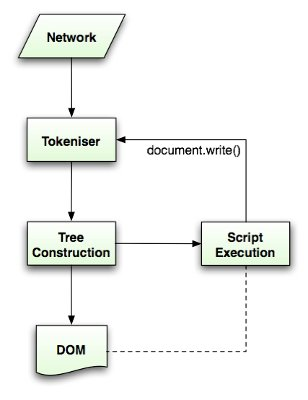
L'algorithme d'analyse est dûˋcrit en dûˋtail par la spûˋcification HTML5. L'algorithme se compose de deux ûˋtapes - la sûˋparation des mots-clûˋs et la construction de l'arbre.
La sûˋparation est l'analyse lexicale, transformer l'entrûˋe en mots-clûˋs. Parmi les mots-clûˋs HTML, on trouve les balises de dûˋbut, de fin, les noms d'attributs et les valeurs d'attributs.
L'analyse lexicale reconnaûÛt le mot-clûˋ, le donne au constructeur de l'arbre et consomme le caractû´re suivant pour reconnaûÛtre le mot-clûˋ suivant. Et ainsi de suite jusqu'û la fin de l'entrûˋe.
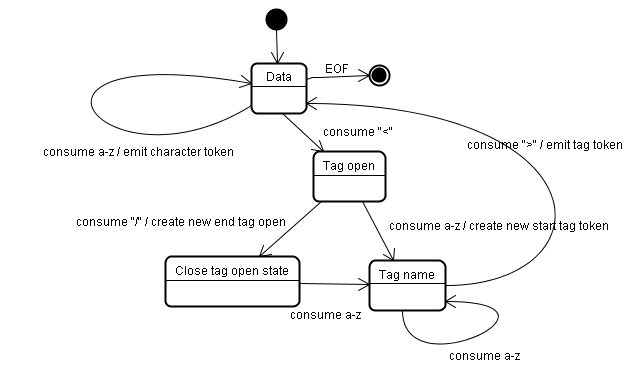
3-2-6. L'algorithme de sûˋparation▲
La sortie de l'algorithme est un mot-clûˋ HTML. L'algorithme est exprimûˋ comme une machine û ûˋtats. Chaque ûˋtat consomme un ou plusieurs caractû´res du flux d'entrûˋe et met û jour l'ûˋtat suivant en fonction de ces caractû´res. La dûˋcision est influencûˋe par l'ûˋtat courant et par l'ûˋtat de la construction de l'arbre. Cela signifie que le mûˆme caractû´re consommûˋ donnera des ûˋtats de sortie diffûˋrents en fonction de l'ûˋtat courant. L'algorithme est trop complexe pour ûˆtre dûˋcrit entiû´rement, alors voyons un exemple simple qui nous aidera û comprendre le principe.
Exemple simple, lire le code HTML suivant :
L'ûˋtat initial est ô¨ donnûˋes ô£. Lorsque le caractû´re < est lu, l'ûˋtat est changûˋ en ô¨ ouvert ô£. Consommer un caractû´re provoque la crûˋation d'un ô¨ dûˋbut de nom ô£, l'ûˋtat est changûˋ en ô¨ nom ô£. L'ûˋtat ne change pas jusqu'û ce que le caractû´re > soit lu, chaque caractû´re ûˋtant ajoutûˋ au nom. Dans notre cas, le mot-clûˋ crûˋûˋ est html.
Lorsque le caractû´re > est atteint, le mot-clûˋ courant est ûˋmis et l'ûˋtat redevient ô¨ donnûˋes ô£. La balise <body> sera traitûˋe par le mûˆme processus. Pour l'instant, les balises html et body ont ûˋtûˋ ûˋmises. Nous sommes maintenant de retour û l'ûˋtat ô¨ donnûˋes ô£. Consommer le caractû´re H de Hello world va provoquer la crûˋation et l'ûˋmission d'un mot-clûˋ caractû´re, cela continue jusqu'û ce que le < de </body> soit atteint. Il y aura ûˋmission d'un mot-clûˋ caractû´re pour chaque caractû´re de Hello world.
Nous sommes maintenant de retour û l'ûˋtat ô¨ ouvert ô£. Consommer le caractû´re suivant / provoquera la crûˋation d'un mot-clûˋ balise de fin et le passage û l'ûˋtat ô¨ nom ô£. Encore une fois nous restons dans cet ûˋtat jusqu'û ce que nous atteignons >. Ensuite le mot-clûˋ est ûˋmis et nous revenons û l'ûˋtat ô¨ donnûˋes ô£. L'entrûˋe </html> sera traitûˋe comme prûˋcûˋdemment.
3-2-7. L'algorithme de construction de l'arbre▲
Lorsque l'analyseur est crûˋûˋ, l'objet Document est crûˋûˋ. Pendant la phase de construction de l'arbre, l'arbre DOM avec le Document dans sa racine est modifiûˋ et les ûˋlûˋments sont ajoutûˋs. Chaque néud ûˋmis par l'analyseur lexical est traitûˋ par le constructeur d'arbre. Pour chacun des mots-clûˋs dûˋfinis par la spûˋcification DOM, un ûˋlûˋment DOM sera crûˋûˋ. Sauf s'il est ajoutûˋ û l'arbre DOM, il est ajoutûˋ û une pile d'ûˋlûˋments ouverts. Cette pile est utilisûˋe pour corriger les dûˋsûˋquilibres d'imbrication et les balises non fermûˋes. L'algorithme est aussi dûˋcrit comme une machine û ûˋtats. Les ûˋtats sont appelûˋs ô¨ modes d'insertion ô£.
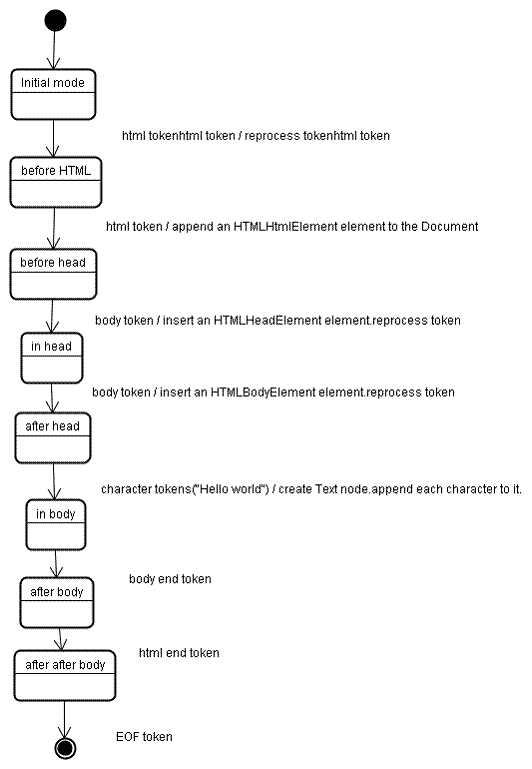
Voyons le processus de construction de l'arbre pour cet exemple :
L'entrûˋe û l'ûˋtape de la construction de l'arbre est une sûˋquence de mots-clûˋs issus de l'analyse lexicale. Le premier ûˋtat est l'ûˋtat ô¨ initial ô£. La rûˋception du mot-clûˋ html provoquera le passage û l'ûˋtat ô¨ avant html ô£ et un nouveau traitement de ce mot-clûˋ pour ce mode. Cela entraûÛnera la crûˋation de l'ûˋlûˋment HTMLHtmlElement qui sera ajoutûˋ û la racine de l'objet Document.
L'ûˋtat sera alors changûˋ en ô¨ avant head ô£. Nous recevons ensuite le mot-clûˋ body. Un HTMLHeadElement est crûˋûˋ implicitement, bien que nous n'avons pas de mot-clûˋ head et il est ajoutûˋ û l'arbre.
Nous passons maintenant de l'ûˋtat ô¨ dans entûˆte ô£ û ô¨ aprû´s entûˆte ô£. Le mot-clûˋ body est traitûˋ û nouveau, un HTMLBodyElement est crûˋûˋ et insûˋrûˋ et l'ûˋtat est ensuite modifiûˋ en ô¨ dans corps ô£.
Les mots-clûˋs caractû´re de la chaûÛne ô¨ Hello world ô£ sont maintenant reûÏus. Le premier va causer la crûˋation et l'insertion d'un néud text et les autres caractû´res seront ajoutûˋs û ce néud.
La rûˋception du mot-clûˋ fin de corps va provoquer le changement d'ûˋtat ô¨ aprû´s corps ô£. Nous allons maintenant recevoir la balise de fin html qui va changer l'ûˋtat en ô¨ aprû´s aprû´s corps ô£. La rûˋception du mot-clûˋ fin de fichier termine l'analyse.
3-2-8. Les actions en fin d'analyse▲
û ce stade, le navigateur va marquer le document comme interactif et lancer l'analyse des scripts marquûˋs comme ô¨ diffûˋrûˋs ô£ - ceux qui doivent ûˆtre exûˋcutûˋs aprû´s que le document a ûˋtûˋ analysûˋ. L'ûˋtat document sera alors rûˋglûˋ sur ô¨ terminûˋ ô£ et un ûˋvûˋnement ô¨ chargement ô£ est dûˋclenchûˋ.
Vous pouvez voir les algorithmes complets pour l'analyse et la construction des arbres dans la spûˋcification HTML5.
3-2-9. La tolûˋrance aux erreurs des navigateurs▲
Vous n'aurez jamais une erreur ô¨ syntaxe invalide ô£ avec une page HTML. Les navigateurs corrigent les contenus invalides et continuent.
Prenez ce code HTML par exemple :
Je dois avoir violûˋ environ un million de rû´gles (mytag n'est pas une balise standard, mauvaise imbrication des balises p et div et plus encore), mais le navigateur le montre quand mûˆme correctement et ne se plaint pas. Ainsi, beaucoup de code de l'analyseur sert û corriger les erreurs des codeurs HTML.
La gestion des erreurs est tout û fait compatible avec les navigateurs, mais ûˋtonnamment, elle ne fait pas partie de la spûˋcification HTML actuelle. Comme les boutons ô¨ Favoris ô£, ô¨ Prûˋcûˋdent ô£ et ô¨ Suivant ô£, c'est juste quelque chose qui s'est dûˋveloppûˋ dans les navigateurs au fil des annûˋes. On connaûÛt des constructions HTML invalides qui se rûˋpû´tent sur de nombreux sites et les navigateurs essayent de les rûˋsoudre d'une maniû´re conforme avec les autres navigateurs.
La spûˋcification HTML5 dûˋfinit certaines de ces exigences. Webkit rûˋsume cela trû´s bien dans les commentaires du dûˋbut de la classe de l'analyseur HTML.
L'analyseur analyse l'entrûˋe sous forme de mot-clûˋ dans le document, en construisant l'arbre du document. Si le document est bien formûˋ, son analyse est simple.
Malheureusement, nous avons û gûˋrer de nombreux documents HTML qui ne sont pas bien formûˋs de sorte que l'analyseur doit ûˆtre tolûˋrant avec les erreurs.
Nous devons faire attention au moins aux conditions d'erreur suivantes :
-
- L'ûˋlûˋment ajoutûˋ est explicitement interdit û l'intûˋrieur de certaines balises extûˋrieures. Dans ce cas, nous devrions fermer toutes les balises jusqu'û celle qui interdit l'ûˋlûˋment et l'ajouter û la suite ;
- Nous ne sommes pas autorisûˋs û ajouter l'ûˋlûˋment directement. Il se pourrait que la personne qui ûˋcrit le document ait oubliûˋ quelques balises entre les deux (ou que la balise entre les deux est en option). Ce pourrait ûˆtre le cas avec les balises HTML suivantes : HEAD BODY TBODY TR TD LI (en ai-je oubliûˋ une ?) ;
- Nous voulons ajouter un ûˋlûˋment de bloc û l'intûˋrieur d'un ûˋlûˋment en ligne. Fermer tous les ûˋlûˋments en ligne jusqu'au bloc supûˋrieur suivant ;
- Si cela ne fonctionne pas, fermer les ûˋlûˋments jusqu'û ûˆtre autorisûˋ û ajouter l'ûˋlûˋment ou ignorer la balise.
Voyons quelques exemples de tolûˋrance aux erreurs de Webkit.
3-2-9-1. </br> û la place de <br>▲
Certains sites utilisent </br> au lieu de <br>. De maniû´re û ûˆtre compatible avec IE et Firefox, Webkit traite cela comme un <br>.
Le code :
2.
3.
4.
if (t->isCloseTag(brTag) && m_document->inCompatMode()) {
reportError(MalformedBRError);
t->beginTag = true;
}
Notez que la gestion d'erreur est interne, elle ne sera pas prûˋsentûˋe û l'utilisateur.
3-2-9-2. Une table parasite▲
Une table parasite est une table û l'intûˋrieur d'une autre, mais pas û l'intûˋrieur d'une cellule.
Comme dans cet exemple :
Webkit va changer la hiûˋrarchie pour deux tables séurs :
Le code :
2.
if (m_inStrayTableContent && localName == tableTag)
popBlock(tableTag);
Webkit utilise une pile pour le contenu des ûˋlûˋments courants, il va dûˋpiler la table interne de la table externe, ces tables seront dûˋsormais séurs.
3-2-9-3. Imbrication de formulaires▲
Dans le cas oû¿ un utilisateur met un formulaire û l'intûˋrieur d'un autre, le deuxiû´me est ignorûˋ.
Le code :
2.
3.
if (!m_currentFormElement) {
m_currentFormElement = new HTMLFormElement(formTag, m_document);
}
3-2-9-4. Une hiûˋrarchie trop profonde▲
Ce commentaire parle de lui-mûˆme.
www.liceo.edu.mx est l'exemple d'un site qui permet d'atteindre un niveau d'imbrication d'environ 1500 balises <b>. Nous n'autoriserons pas plus de 20 balises imbriquûˋes du mûˆme type avant de toutes les ignorer.
2.
3.
4.
5.
6.
7.
8.
bool HTMLParser::allowNestedRedundantTag(const AtomicString& tagName)
{
unsigned i = 0;
for (HTMLStackElem* curr = m_blockStack;
i < cMaxRedundantTagDepth && curr && curr->tagName == tagName;
curr = curr->next, i++) { }
return i != cMaxRedundantTagDepth;
}
3-2-9-5. Balises HTML ou body fermantes mal placûˋes▲
Encore une fois, le commentaire parle de lui-mûˆme.
La prise en charge de HTML vraiment mal formûˋ. Nous ne fermons jamais la balise body, car certaines pages Web stupides la ferment avant la fin rûˋelle du document. Nous nous basons uniquement sur le end() pour tout fermer.
2.
if (t->tagName == htmlTag || t->tagName == bodyTag )
return;
Ainsi, codeurs Web, mûˋfiez-vous, û moins que vous ne souhaitiez apparaûÛtre comme un exemple dans un morceau de code de la tolûˋrance aux erreurs de Webkit, ûˋcrivez un code HTML bien formûˋ.
3-3. L'analyse CSS▲
Vous rappelez-vous les concepts de l'analyse dans l'introduction ? Eh bien, contrairement û HTML, CSS est une grammaire sans contexte, elle peut ûˆtre analysûˋe û l'aide des types d'analyseurs dûˋcrits dans l'introduction. En fait, la spûˋcification CSS dûˋfinit sa grammaire lexicale et syntaxique.
Voyons quelques exemples.
La grammaire lexicale (le vocabulaire) est dûˋfinie par les expressions rûˋguliû´res pour chaque mot-clûˋ :
2.
3.
4.
5.
6.
7.
8.
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/
num [0-9]+|[0-9]*"."[0-9]+
nonascii [\200-\377]
nmstart [_a-z]|{nonascii}|{escape}
nmchar [_a-z0-9-]|{nonascii}|{escape}
name {nmchar}+
ident {nmstart}{nmchar}*
"ident" is short for identifier, like a class name. "name" is an element id (that is referred by "#" )
La syntaxe de la grammaire est dûˋcrite en BNF :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
selector
: simple_selector [ combinator selector | S+ [ combinator? selector ]? ]?
;
simple_selector
: element_name [ HASH | class | attrib | pseudo ]*
| [ HASH | class | attrib | pseudo ]+
;
class
: '.' IDENT
;
element_name
: IDENT | '*'
;
attrib
: '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S*
[ IDENT | STRING ] S* ] ']'
;
pseudo
: ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ]
;
Explication, un jeu de rû´gles possû´de la structure suivante :
2.
3.
4.
div.error , a.error {
color:red;
font-weight:bold;
}
div.error et a.error sont des sûˋlecteurs. La partie û l'intûˋrieur des accolades contient les rû´gles qui sont appliquûˋes par cet ensemble de rû´gles. Cette structure est dûˋfinie formellement dans cette dûˋfinition :
2.
3.
4.
ruleset
: selector [ ',' S* selector ]*
'{' S* declaration [ ';' S* declaration ]* '}' S*
;
Cela signifie qu'un ensemble de rû´gles est un sûˋlecteur ou ûˋventuellement un ensemble de sûˋlecteurs sûˋparûˋs par une virgule et des espaces (S reprûˋsente un espace). Un jeu de rû´gles contient des accolades et û l'intûˋrieur, une dûˋclaration ou ûˋventuellement un certain nombre de dûˋclarations sûˋparûˋes par un point-virgule. ô¨ dûˋclaration ô£ et ô¨ sûˋlecteurô£ seront dûˋfinis dans les dûˋfinitions BNF suivantes.
3-3-1. L'analyseur CSS de Webkit▲
Webkit utilise les gûˋnûˋrateurs d'analyseur Flex et Bison pour crûˋer des analyseurs de grammaire CSS. Si vous vous souvenez de l'introduction aux analyseurs, Bison crûˋûˋ un analyseur de bas en haut dûˋcalage-rûˋduction. Firefox utilise un analyseur de haut en bas ûˋcrit manuellement. Dans les deux cas, chaque fichier CSS est analysûˋ dans une feuille de style, chaque objet contient des rû´gles CSS. Les objets de la rû´gle CSS contiennent des objets de sûˋlection et de dûˋclaration ainsi que d'autres objets de la grammaire CSS.

3-4. L'ordre d'analyse des scripts et des feuilles de style▲
3-4-1. Les scripts▲
Le modû´le du Web est synchrone. Les auteurs s'attendent û ce que les scripts soient analysûˋs et exûˋcutûˋs immûˋdiatement lorsque l'analyseur atteint une balise <script>. L'analyse du document s'arrûˆte jusqu'û ce que le script ait ûˋtûˋ exûˋcutûˋ. Si le script est externe, alors la ressource doit ûˆtre d'abord rûˋcupûˋrûˋe sur le rûˋseau, ceci est fait aussi de maniû´re synchrone, l'analyse s'arrûˆte jusqu'û ce que la ressource soit rûˋcupûˋrûˋe. C'ûˋtait le modû´le durant de nombreuses annûˋes et c'est ûˋgalement spûˋcifiûˋ dans le HTML 4 et 5. Les auteurs pouvaient marquer le script comme ô¨ reportûˋ ô£ et donc il n'interrompait pas l'analyse du document, mais ûˋtait exûˋcutûˋ aprû´s avoir ûˋtûˋ analysûˋ. HTML5 ajoute une option pour marquer le script comme asynchrone de sorte qu'il soit analysûˋ et exûˋcutûˋ par un thread diffûˋrent.
3-4-2. L'analyse spûˋculative▲
Aussi bien Webkit que Firefox font cette optimisation. Pendant l'exûˋcution de scripts, un autre thread analyse le reste du document et dûˋcouvre les autres ressources qui doivent ûˆtre chargûˋes depuis le rûˋseau et les charge. De cette faûÏon, les ressources peuvent ûˆtre chargûˋes sur des connexions parallû´les et la vitesse globale est meilleure. Remarquez que l'analyse spûˋculative ne modifie pas l'arborescence DOM, ceci est laissûˋ û la charge de l'analyseur principal, elle ne fait qu'analyser les rûˋfûˋrences û des ressources externes, comme les scripts externes, les feuilles de style et les images.
3-4-3. Les feuilles de style▲
D'autre part, les feuilles de style ont un modû´le diffûˋrent. Sur le plan conceptuel, il semble que puisque les feuilles de style ne changent pas l'arborescence DOM, il n'y a aucune raison d'attendre leur chargement et d'arrûˆter l'analyse syntaxique du document. Il y a tout de mûˆme un problû´me, pour les scripts demandant des informations de style durant l'analyse du document. Si le style n'est pas encore chargûˋ et analysûˋ, le script va obtenir des rûˋponses fausses et apparemment, cela a causûˋ beaucoup de problû´mes. Cela semble ûˆtre un cas limite, mais c'est tout û fait commun. Firefox bloque tous les scripts tant qu'une feuille de style est en cours de chargement et d'analyse. Webkit bloque les scripts seulement quand ils tentent d'accûˋder û certaines propriûˋtûˋs de style qui peuvent ûˆtre affectûˋes par des feuilles de style non encore chargûˋes.
4. La construction de l'arbre de rendu▲
Pendant que l'arbre DOM est en cours de construction, le navigateur construit aussi un autre arbre, l'arbre de rendu. Cet arbre est constituûˋ des ûˋlûˋments visuels dans l'ordre dans lequel ils apparaissent. Il est la reprûˋsentation visuelle du document. Le but de cet arbre est de permettre le dessin du contenu dans l'ordre correct.
Firefox appelle ces ûˋlûˋments dans l'arbre de rendu ô¨ images ô£. Webkit utilise le terme de rendu ou objet de rendu.
Un rendu sait faire sa mise en page et se peindre, lui et ses enfants.
La classe Webkits RenderObject, la classe de base des rendus, a la dûˋfinition suivante :
2.
3.
4.
5.
6.
7.
8.
class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
Chaque rendu reprûˋsente une zone rectangulaire correspondant le plus souvent û la boite du néud CSS, tel que dûˋcrit par la spûˋcification CSS2. Il contient des informations gûˋomûˋtriques comme sa largeur, sa hauteur et sa position.
Le type de la boite est affectûˋ par l'attribut de style display qui est pertinent pour le néud (voir la section de ). Voici le code Webkit pour dûˋcider quel type de rendu devrait ûˆtre crûˋûˋ pour un néud DOM, selon l'attribut display.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0;
switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
}
return o;
}
Le type de l'ûˋlûˋment est ûˋgalement considûˋrûˋ, par exemple les champs de formulaires et les tables ont des cadres spûˋciaux.
Avec Webkit, si un ûˋlûˋment veut crûˋer un rendu spûˋcial il remplace la mûˋthode createRenderer. Le rendu pointe vers les objets de style qui contiennent les informations non gûˋomûˋtriques.
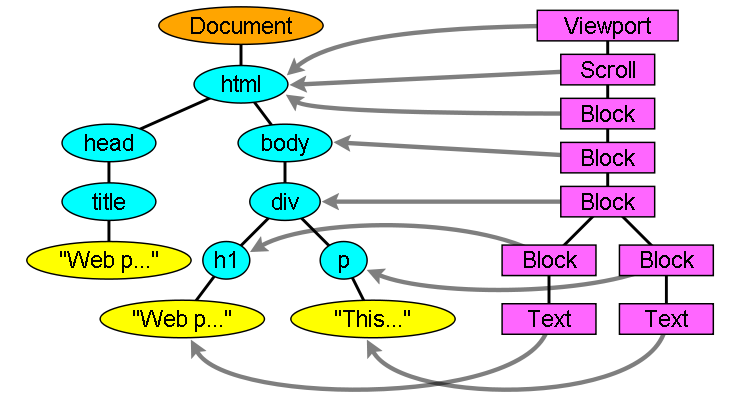
4-1. La relation entre l'arbre DOM et l'arbre de rendu▲
Les rendus correspondent aux ûˋlûˋments DOM, mais la relation n'est pas une relation un-û -un. Les ûˋlûˋments DOM non visuels ne sont pas insûˋrûˋs dans l'arbre de rendu. Par exemple, l'ûˋlûˋment head. Les ûˋlûˋments dont l'attribut display est positionnûˋ û none n'apparaûÛtront pas dans l'arbre de rendu (en revanche, les ûˋlûˋments avec l'attribut display hidden seront prûˋsents dans l'arbre).
Il y a des ûˋlûˋments DOM qui correspondent û plusieurs objets visuels. Ce sont gûˋnûˋralement des ûˋlûˋments de structure complexe qui ne peuvent ûˆtre dûˋcrits par un simple rectangle. Par exemple, l'ûˋlûˋment select possû´de trois rendus, un pour la zone d'affichage, un pour la zone de liste dûˋroulante et un pour le bouton. De mûˆme, lorsque le texte est scindûˋ en plusieurs lignes, car la largeur n'est pas suffisante pour tenir sur une seule, les nouvelles lignes seront ajoutûˋes comme des rendus supplûˋmentaires.
Un autre exemple de rendus multiples concerne le HTML mal formûˋ. Selon les spûˋcifications CSS, un ûˋlûˋment inline doit contenir soit des blocs d'ûˋlûˋments ou alors seulement des ûˋlûˋments inline. En cas de contenu mixte, des rendus anonymes seront crûˋûˋs pour envelopper les ûˋlûˋments inline.
Certains objets rendus correspondent û un néud DOM, mais pas au mûˆme endroit dans l'arbre. Les ûˋlûˋments flottants et ceux avec un positionnement absolu sont hors du flux, ils sont placûˋs dans un endroit diffûˋrent de l'arbre et appliquûˋs au cadre rûˋel. Leur emplacement rûˋservûˋ est lû oû¿ ils auraient dû£ ûˆtre.
4-2. La construction de l'arbre▲
Avec Firefox, la prûˋsentation s'enregistre comme un ûˋcouteur pour les mises û jour du DOM. La prûˋsentation dûˋlû´gue la crûˋation des cadres û FrameConstructor et le constructeur dûˋcide du style (voir ) et crûˋe le cadre.
Avec Webkit le processus de rûˋsolution du style et la crûˋation du rendu sont appelûˋs ô¨ attachement ô£. Chaque néud DOM possû´de une mûˋthode attach. L'attachement est synchrone, l'insertion d'un néud dans l'arbre DOM appelle la mûˋthode attach du nouveau néud.
Le traitement des balises html et body aboutit û la construction de la racine de l'arbre de rendu. L'objet de rendu racine correspond û ce que la spûˋcification CSS appelle le bloc conteneur, le bloc le plus haut qui contient tous les autres blocs. Ses dimensions sont celles de la fenûˆtre d'affichage du navigateur. Firefox l'appelle ViewPortFrame et Webkit l'appelle RenderView. C'est l'objet de rendu pointûˋ par le document. Le reste de l'arbre est construit au fur et û mesure de l'insertion des néuds DOM. Voir la spûˋcification CSS2 sur le modû´le de traitement.
4-3. Calcul du style▲
Construire l'arbre de rendu nûˋcessite le calcul des propriûˋtûˋs visuelles de chaque objet de rendu. Ceci est fait en calculant les propriûˋtûˋs de style de chaque ûˋlûˋment.
Le style inclut des feuilles de style d'origines diverses, les ûˋlûˋments de style inline et les propriûˋtûˋs visuelles dans le code HTML (comme la propriûˋtûˋ bgcolor). Celui-ci est traduit en correspondance des propriûˋtûˋs de style CSS.
Les origines des feuilles de style sont les feuilles de style par dûˋfaut du navigateur ; les feuilles de style fournies par l'auteur de la page et les feuilles de style de l'utilisateur (qui sont des feuilles de style fournies par l'utilisateur : les navigateurs vous permettent de dûˋfinir votre style prûˋfûˋrûˋ. Avec Firefox, par exemple, cela est fait en plaûÏant une feuille de style dans le rûˋpertoire ô¨ Firefox profile ô£").
Le calcul du style fait apparaûÛtre quelques difficultûˋs :
- Les donnûˋes d'un style peuvent ûˆtre trû´s importantes du fait de nombreuses propriûˋtûˋs de style, cela peut causer des problû´mes de mûˋmoire ;
- Trouver les rû´gles de correspondance pour chaque ûˋlûˋment peut provoquer des problû´mes de performances si ce n'est pas optimisûˋ. Parcourir la liste de toutes les rû´gles pour chaque ûˋlûˋment est une lourde tûÂche. Les sûˋlecteurs peuvent avoir une structure complexe qui peut provoquer le processus d'appariement au dûˋbut sur un chemin apparemment prometteur et qui a fait ses preuves pour devenir ensuite futile, une autre voie doit alors ûˆtre ûˋvaluûˋe.
Par exemple, ce sûˋlecteur composûˋ :
Les rû´gles du code suivant s'appliquent û un <div> qui est le descendant de trois <div>. Supposons que vous voulez vûˋrifier si la rû´gle s'applique pour un ûˋlûˋment <div> donnûˋ. Vous choisissez un certain chemin dans l'arbre pour vûˋrification. Vous pouvez avoir besoin de parcourir toute l'arborescence de néuds juste pour voir qu'il y a seulement deux <div> et que la rû´gle ne s'applique donc pas. Vous devez alors essayer d'autres chemins dans l'arbre.
Sélectionnez1.
2.
3.div div div div{...} - L'application des rû´gles implique des rû´gles de cascade assez complexes qui dûˋfinissent leur hiûˋrarchie.
Voyons comment les navigateurs font face û ces problû´mes.
4-3-1. Le partage des donnûˋes de style▲
Les néuds de Webkit rûˋfûˋrencent des objets style (RenderStyle) Ces objets peuvent ûˆtre partagûˋs par les néuds sous certaines conditions. Les néuds sont frû´res ou cousins et :
- Les ûˋlûˋments doivent ûˆtre dans le mûˆme ûˋtat en ce qui concerne la souris (par exemple, on ne peut ûˆtre en mode :hover si l'autre ne l'est pas) ;
- Aucun ûˋlûˋment ne doit avoir un identifiant ;
- Les noms de balises doivent correspondre ;
- Les attributs de classe doivent correspondre ;
- L'ensemble des attributs associûˋs doivent ûˆtre identiques ;
- L'ûˋtat du lien doit correspondre ;
- L'ûˋtat du focus doit correspondre ;
- Aucun ûˋlûˋment ne doit ûˆtre affectûˋ par un sûˋlecteur d'attribut ; affectûˋ est dûˋfini comme ayant une correspondance avec un sûˋlecteur contenant un sûˋlecteur d'attribut quelle que soit sa position dans le sûˋlecteur global ;
- Il ne doit pas y avoir d'attribut de style sur les ûˋlûˋments ;
- Il ne doit y avoir aucun sûˋlecteur d'enfants. WebCore utilise simplement un commutateur global lorsqu'un sûˋlecteur d'enfant est rencontrûˋ et dûˋsactive le partage de style pour le document entier quand ils sont prûˋsents. Cela comprend le sûˋlecteur + et les sûˋlecteurs comme :first-child et :last-child.
4-3-2. L'arbre des rû´gles de Firefox▲
Firefox dispose de deux arbres supplûˋmentaires pour un calcul plus facile du style, l'arbre des rû´gles et l'arbre de contexte de style. Webkit a aussi des objets de style, mais ils ne sont pas stockûˋs dans un arbre, comme l'arbre de contexte de style, seul le néud DOM pointe sur son style.

Les contextes de style contiennent des valeurs finales. Les valeurs sont calculûˋes en appliquant toutes les rû´gles d'appariement dans le bon ordre et en effectuant les manipulations qui les transforment de valeurs logiques û valeurs concrû´tes. Par exemple, si la valeur logique est le pourcentage par rapport û l'ûˋcran, il sera calculûˋ et transformûˋ en unitûˋs absolues. L'idûˋe derriû´re l'arbre des rû´gles est trû´s intelligente. Elle permet de partager ces valeurs entre les néuds pour ûˋviter de les calculer û nouveau. Cela ûˋconomise aussi de l'espace.
L'ensemble des rû´gles adaptûˋes sont stockûˋes dans un arbre. Les néuds du bas d'un chemin sont prioritaires. L'arbre contient tous les chemins pour la correspondance de rû´gles qui ont ûˋtûˋ trouvûˋes. Le stockage des rû´gles se fait paresseusement. L'arbre n'est pas calculûˋ au dûˋbut de chaque néud, mais û chaque fois qu'un style de néud doit ûˆtre calculûˋ, le chemin calculûˋ est ajoutûˋ û l'arbre.
L'idûˋe est de voir l'arbre des chemins comme des mots dans un dictionnaire. Disons que nous avons dûˋjû calculûˋ cet arbre rû´gle :
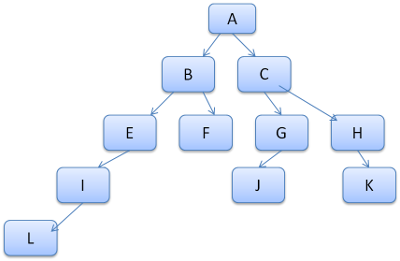
Supposons que nous devions faire correspondre des rû´gles pour un autre ûˋlûˋment dans l'arborescence de contenu et que nous trouvons que les rû´gles appariûˋes (dans le bon ordre) sont B - E - I. Nous avons dûˋjû ce chemin dans l'arbre, car nous avons dûˋjû calculûˋ le trajet A - B - E - I - L. Nous avons maintenant moins de travail û faire.
Voyons comment cet arbre nous permet d'ûˋconomiser du travail.
4-3-2-1. La division par structure▲
Les contextes de style sont divisûˋs en structures. Ces structures contiennent des informations de style pour une certaine catûˋgorie comme la bordure ou la couleur. Toutes les propriûˋtûˋs dans une structure sont hûˋritûˋes ou non hûˋritûˋes. Les propriûˋtûˋs hûˋritûˋes sont des propriûˋtûˋs qui ne sont pas dûˋfinies par l'ûˋlûˋment, elles sont hûˋritûˋes du parent. Les propriûˋtûˋs non hûˋritûˋes (appelûˋes propriûˋtûˋs ô¨ remise û zûˋro ô£) utilisent des valeurs par dûˋfaut si elles ne sont pas dûˋfinies.
L'arbre nous aide en mettant en cache les structures (contenant les valeurs finales calculûˋes) dans l'arborescence. L'idûˋe est que si le néud du bas n'a pas fourni une dûˋfinition pour une structure alors une structure mise en cache pour un néud supûˋrieur peut ûˆtre utilisûˋe.
4-3-2-2. Calculer les contextes de style en utilisant l'arbre des rû´gles▲
Lors du calcul du contexte de style pour un ûˋlûˋment donnûˋ, on calcule d'abord un chemin dans l'arbre des rû´gles ou on en utilise un existant. Nous commenûÏons alors par appliquer les rû´gles dans le chemin pour combler les structures dans notre nouveau contexte style. Nous commenûÏons û la partie basse du chemin, celui avec la plus haute prioritûˋ (gûˋnûˋralement le sûˋlecteur le plus spûˋcifique) et parcourir l'arborescence jusqu'û ce que notre structure soit pleine. S'il n'y a pas de spûˋcification pour la structure dans ce néud rû´gle, alors nous pouvons grandement optimiser, on remonte l'arborescence jusqu'û ce qu'on trouve un néud qui satisfait pleinement et nous pointons tout simplement dessus, c'est la meilleure optimisation, la structure entiû´re est partagûˋe. Cela permet d'ûˋconomiser le calcul des valeurs finales et la mûˋmoire.
Si nous trouvons des dûˋfinitions partielles, nous remontons l'arbre jusqu'û ce que la structure soit complû´te.
Si nous n'avons pas trouvûˋ de dûˋfinitions de notre structure, alors, dans le cas oû¿ la structure est de type ô¨ hûˋritûˋ ô£, nous pointons vers la structure du parent dans l'arborescence des contextes, dans ce cas, nous avons ûˋgalement rûˋussi û partager la structure. Si c'est une structure ô¨ remise û zûˋro ô£, alors les valeurs par dûˋfaut sont utilisûˋes.
Si le néud le plus spûˋcifique ajoute des valeurs, alors nous devons faire quelques calculs supplûˋmentaires pour la transformer en valeurs rûˋelles. Ensuite nous mettons en cache le rûˋsultat dans le néud de l'arbre de sorte qu'il puisse ûˆtre utilisûˋ par des enfants.
Dans le cas oû¿ un ûˋlûˋment a un frû´re qui pointe vers le néud de l'arbre, alors le contexte de style complet peut ûˆtre partagûˋ entre eux.
Voyons un exemple, supposons que nous ayons ce HTML :
Et les rû´gles suivantes :
2.
3.
4.
5.
6.
div {margin:5px;color:black}
.err {color:red}
.big {margin-top:3px}
div span {margin-bottom:4px}
#div1 {color:blue}
#div2 {color:green}
Pour simplifier les choses, disons que nous devons remplir seulement deux structures, la structure couleur et la structure marge. La structure couleur contient un seul membre, la couleur. La structure marge contient les quatre cûÇtûˋs.
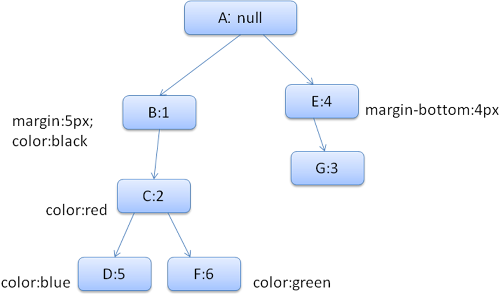
L'arbre de rû´gles rûˋsultant ressemblera û ceci (les néuds sont identifiûˋs par le nom du néud et le numûˋro de la rû´gle sur laquelle ils pointent) :
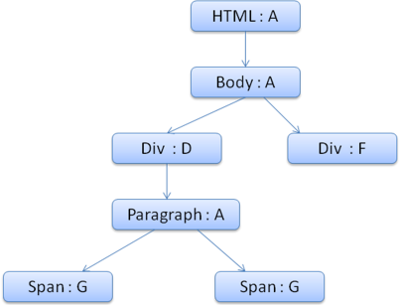
L'arbre des contextes ressemblera û ceci (le nom de néud est le nom de rû´gle gûˋnûˋrale vers laquelle il pointe) :
Supposons que nous analysions le code HTML et que nous arrivions û la deuxiû´me balise <div>. Nous devons crûˋer un cadre de style pour ce néud et remplir ses structures style.
Nous allons faire correspondre les rû´gles et dûˋcouvrir que les rû´gles correspondantes pour le <div> sont 1, 2 et 6. Cela signifie qu'il y a dûˋjû un chemin d'accû´s existant dans l'arborescence que notre ûˋlûˋment peut utiliser, nous avons juste besoin d'ajouter un autre néud pour la rû´gle 6 (le néud F dans l'arbre de rû´gles).
Nous allons crûˋer un contexte de style et le mettre dans l'arbre des contextes. Le nouveau contexte de style va pointer vers le néud F dans l'arbre de rû´gles.
Nous avons maintenant besoin de remplir les structures du style. Nous allons commencer par remplir la structure de marge. Puisque la rû´gle du néud F ne modifie pas la structure de marge, nous pouvons remonter dans l'arbre jusqu'û ce qu'on trouve une structure en cache calculûˋe dans un néud d'insertion prûˋcûˋdent et l'utiliser. Nous allons la trouver avec le néud B, qui est le néud le plus ûˋlevûˋ avec les rû´gles de marge spûˋcifiûˋes.
Nous avons une dûˋfinition de la structure couleur, donc on ne peut pas utiliser une structure en cache. Puisque la couleur n'a qu'un attribut, nous n'avons pas besoin d'aller dans l'arbre pour en remplir d'autres. Nous allons calculer la valeur finale (convertir la chaûÛne en RVB, etc.) et mettre en cache la structure calculûˋe sur ce néud.
Le travail sur le deuxiû´me ûˋlûˋment <span> est encore plus facile. Nous faisons correspondre les rû´gles et arrivons û la conclusion qu'il pointe sur la rû´gle G, comme le <span> prûˋcûˋdent. Puisque ce sont des frû´res qui pointent vers le mûˆme néud, nous pouvons partager le contexte de style tout simplement en pointant dans le contexte du <span> prûˋcûˋdent.
Pour les structures qui contiennent des rû´gles qui sont hûˋritûˋes du parent, la mise en cache se fait sur l'arbre de contexte (la propriûˋtûˋ de couleur est en fait hûˋritûˋe, mais Firefox la traite comme ô¨ remise û zûˋro ô£ et la met en cache sur l'arbre de rû´gles).
Par exemple, si nous ajoutons des rû´gles de polices dans un paragraphe :
p {font-family:Verdana;font size:10px;font-weight:bold}
Alors, l'ûˋlûˋment de paragraphe, qui est un enfant de <div> dans l'arbre de contexte, aurait pu partager la structure de police de son parent. Cela serait le cas si aucune rû´gle de police n'avait ûˋtûˋ spûˋcifiûˋe pour le paragraphe.
Avec Webkit, qui ne dispose pas d'un arbre de rû´gles, les dûˋclarations correspondantes sont traversûˋes quatre fois. En premier, les propriûˋtûˋs non importantes (propriûˋtûˋs qui doivent ûˆtre appliquûˋes d'abord parce que d'autres dûˋpendent d'elles, comme l'affichage) sont appliquûˋes, ensuite, les propriûˋtûˋs importantes, puis les propriûˋtûˋs normales et enfin les propriûˋtûˋs normales pour les rû´gles importantes. Cela signifie que les propriûˋtûˋs qui apparaissent plusieurs fois seront rûˋsolues selon l'ordre de cascade correct. C'est le dernier qui l'emporte.
Donc, pour rûˋsumer, le partage des objets style (tout ou partie des structures û l'intûˋrieur) rûˋsout les problû´mes 1 et 3. L'arbre de rû´gles Firefox contribue ûˋgalement û l'application des propriûˋtûˋs dans le bon ordre.
4-3-3. Manipuler les rû´gles pour une recherche plus facile▲
Il existe plusieurs sources pour les rû´gles de style :
- les rû´gles CSS, soit dans des feuilles de style externes, soit dans des balises style :Sélectionnez1.
p{color:blue} - des attributs de style en ligne comme :Sélectionnez1.
<pstyle="color:blue"/> - des attributs HTML visuels (qui sont mappûˋs aux rû´gles de style correspondantes) :
<p bgcolor="blue" />
Les deux derniers sont facilement adaptûˋs û l'ûˋlûˋment, car ils possû´dent les attributs de style et attributs HTML qui peuvent ûˆtre indexûˋs en utilisant l'ûˋlûˋment comme clûˋ.
Comme indiquûˋ prûˋcûˋdemment dans le problû´me 2, la recherche de la rû´gle CSS peut ûˆtre plus compliquûˋe. Pour rûˋsoudre cette difficultûˋ, les rû´gles sont manipulûˋes pour en faciliter l'accû´s.
Aprû´s l'analyse de la feuille de style, les rû´gles sont ajoutûˋes û une des tables de hachage, en fonction de la sûˋlection. Il y a des tables dont l'index est l'identifiant, le nom de classe, le nom de balise et une table gûˋnûˋrale pour tout ce qui ne rentre pas dans ces catûˋgories. Si le sûˋlecteur est un identifiant, la rû´gle sera ajoutûˋe û la table des identifiants, s'il s'agit d'une classe, elle sera ajoutûˋe û la table des classes, etc.
Cette manipulation rend beaucoup plus facile la recherche des rû´gles. Il n'est pas nûˋcessaire de regarder dans chaque dûˋclaration, nous pouvons extraire les rû´gles applicables û un ûˋlûˋment û partir des tables. Cette optimisation ûˋlimine 95 % et plus des rû´gles, de sorte qu'elles ne devraient mûˆme pas ûˆtre prises en compte lors du processus d'appariement ().
Voyons par exemple les rû´gles de style suivantes :
La premiû´re rû´gle est insûˋrûˋe dans la table des classes. La seconde dans la table des identifiants et la troisiû´me dans la table des balises.
Pour le morceau HTML suivant :
Nous allons d'abord essayer de trouver des rû´gles pour l'ûˋlûˋment p. La table des classes contiendra une clûˋ error en vertu de laquelle la rû´gle de p.error est trouvûˋe. La balise div aura une rû´gle qui correspond dans la table des identifiants (la clûˋ est l'identifiant) et la table des balises. Ainsi, le travail qui reste û faire est de savoir quelles sont les rû´gles qui ont ûˋtûˋ extraites par les index qui correspondent vraiment.
Par exemple, si la rû´gle de la div est :
table div {margin:5px}
elle sera toujours extraite de la table des balises, parce que la clûˋ est le sûˋlecteur de droite, mais elle ne correspondrait pas û notre ûˋlûˋment div, qui n'a pas de parent de type table.
û la fois Webkit et Firefox font cette manipulation.
4-3-4. Appliquer les rû´gles dans l'ordre correct▲
L'objet style a des propriûˋtûˋs correspondant û chaque attribut visuel (tous les attributs CSS, mais plus gûˋnûˋriques). Si la propriûˋtûˋ n'est dûˋfinie par aucune des rû´gles adaptûˋes, alors certaines propriûˋtûˋs peuvent ûˆtre hûˋritûˋes du style de l'ûˋlûˋment parent. D'autres propriûˋtûˋs ont des valeurs par dûˋfaut.
Le problû´me commence lorsqu'il y a plus d'une dûˋfinition, voici l'ordre pour rûˋsoudre ce problû´me.
4-3-4-1. L'ordre des feuilles de style▲
La dûˋclaration d'une propriûˋtûˋ de style peut apparaûÛtre dans plusieurs feuilles de style et plusieurs fois û l'intûˋrieur d'une mûˆme feuille de style. Cela signifie que l'ordre d'application des rû´gles est trû´s important. C'est ce qu'on appelle la "cascade" des commandes. Selon la spûˋcification CSS2, l'ordre en cascade est (de bas en haut) :
- Les dûˋclarations du navigateur ;
- Les dûˋclarations normales de l'utilisateur ;
- Les dûˋclarations normales de l'auteur ;
- Les dûˋclarations importantes de l'auteur ;
- Les dûˋclarations importantes de l'utilisateur ;
Les dûˋclarations du navigateur sont les moins importantes et celles de l'utilisateur supplantent celles de l'auteur uniquement si ces dûˋclarations sont importantes. Les dûˋclarations de mûˆme importance sont triûˋes par et par ordre dans lequel elles apparaissent. Les attributs HTML visuels sont convertis en dûˋclarations CSS. Ils sont traitûˋs comme des rû´gles d'auteur de faible prioritûˋ.
4-3-4-2. La spûˋcificitûˋ▲
Le sûˋlecteur de spûˋcificitûˋ est dûˋfini par les spûˋcifications CSS2 comme cela :
- compter 1 si la dûˋclaration est issue d'un attribut style plutûÇt qu'une rû´gle d'un sûˋlecteur, 0 sinon (= a) ;
- compter le nombre d'attributs identifiant dans le sûˋlecteur (= b) ;
- compter le nombre d'autres attributs et de pseudoclasse dans le sûˋlecteur (= c) ;
- compter le nombre de noms d'ûˋlûˋments et de pseudoûˋlûˋments dans le sûˋlecteur (= d) ;
La concatûˋnation des quatre nombres a-b-c-d (dans un systû´me de numûˋration û base large) donne la spûˋcificitûˋ.
La base que vous devez utiliser est dûˋfinie par le nombre le plus ûˋlevûˋ que vous avez dans l'une des catûˋgories.
Par exemple, si a = 14, vous pouvez utiliser la base hexadûˋcimale. Dans le cas peu probable oû¿ vous aurez a = 17, vous aurez besoin d'une base 17. La situation peut se produire avec un sûˋlecteur comme ceci : html body div div p ... (17 balises dans votre sûˋlection, peu probable).
Quelques exemples :
2.
3.
4.
5.
6.
7.
8.
9.
10.
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
4-3-4-3. Trier les rû´gles▲
Une fois que les rû´gles sont trouvûˋes, elles sont triûˋes d'aprû´s les rû´gles de cascade. Webkit utilise un tri û bulles pour les petites listes et un tri par fusion pour les grandes. Webkit met en éuvre le tri en remplaûÏant l'opûˋrateur ô¨ > ô£ pour les rû´gles :
2.
3.
4.
5.
6.
static bool operator >(CSSRuleData& r1, CSSRuleData& r2)
{
int spec1 = r1.selector()->specificity();
int spec2 = r2.selector()->specificity();
return (spec1 == spec2) : r1.position() > r2.position() : spec1 > spec2;
}
4-4. Processus graduel▲
Webkit utilise un indicateur qui marque les feuilles de style haut niveau (y compris les rû´gles @imports) chargûˋes. Si le style n'est pas complû´tement chargûˋ lors de l'attachement, des jokers sont utilisûˋs et le document est marquûˋ. Ils seront recalculûˋs une fois les feuilles de style chargûˋes.
5. La mise en page▲
Quand le rendu est crûˋûˋ et ajoutûˋ û l'arbre, il n'a ni position ni taille. Calculer ces valeurs est appelûˋ ô¨ mise en page ô£ ou ô¨ refusion ô£.
HTML utilise un modû´le de mise en page basûˋ sur une fusion, ce qui signifie que, la plupart du temps, il est possible d'en calculer la gûˋomûˋtrie en une seule passe. Les ûˋlûˋments qui sont ajoutûˋs ô¨ dans le flux ô£ n'affectent gûˋnûˋralement pas la gûˋomûˋtrie des ûˋlûˋments qui y ûˋtaient dûˋjû , de telle sorte que la mise en page se fait de gauche û droite et de haut en bas pour tout le document. On compte quelques exceptions - par exemple, le rendu des tableaux HTML peut prendre plusieurs passes (3.5).
Le systû´me de coordonnûˋes est relatif au cadre principal. Les coordonnûˋes sont initialisûˋes en haut û gauche.
La mise en page est un processus rûˋcursif. Il commence û la racine du moteur de rendu, ce qui correspond û l'ûˋlûˋment <html> du document HTML. Elle continue de maniû´re rûˋcursive dans une partie ou toute la hiûˋrarchie des cadres, en calculant les informations gûˋomûˋtriques pour chaque moteur de rendu qui le requiert.
La position du moteur de rendu racine est (0, 0) et ses dimensions correspondent û la zone d'affichage - la part visible de la fenûˆtre du navigateur.
Tous les moteurs de rendu ont une mûˋthode de ô¨ mise en page ô£ ou de ô¨ refusion ô£, chacun invoque la mûˋthode de mise en page de ses enfants quand il en a besoin.
5-1. Le systû´me du bit sale▲
Pour ne pas effectuer û nouveau une mise en page complû´te û chaque petit changement, les navigateurs utilisent un systû´me de ô¨ bit sale ô£. Un moteur de rendu qui est changûˋ ou ajoutûˋ se marque ainsi que ses enfants comme ô¨ sales ô£ (ils doivent ûˆtre remis en page).
Gûˋnûˋralement, les navigateurs distinguent deux drapeaux : ô¨ sale ô£ et ô¨ enfants sales ô£. Ce dernier signifie que, bien que le moteur de rendu lui-mûˆme corresponde toujours au contenu HTML, il y a au moins un enfant qui doit ûˆtre remis en page.
5-2. Mise en page globale et incrûˋmentale▲
La mise en page peut s'effectuer sur tout l'arbre de rendu - on l'appelle ô¨ mise en page globale ô£. Cela peut arriver suite û :
- Un changement dans le style global, qui affecte tout le contenu, comme un changement de la taille de police ;
- Un redimensionnement de la fenûˆtre.
La mise en page peut ûˋgalement ûˆtre incrûˋmentale, auquel cas seuls les ûˋlûˋments sales seront remis en page (ce qui peut causer quelques dommages, qui causeront des remises en page supplûˋmentaires).
Cette mise en page incrûˋmentale est dûˋclenchûˋe (de maniû´re asynchrone) quand les moteurs de rendu sont sales, par exemple quand de nouveaux objets sont ajoutûˋs û la fin de l'arbre de rendu aprû´s que du contenu supplûˋmentaire est arrivûˋ du rûˋseau et est ajoutûˋ û l'arbre DOM.
5-3. Mise en page synchrone ou non▲
La mise en page incrûˋmentale est effectuûˋe de maniû´re asynchrone. Firefox met en file d'attente les ô¨ commandes de refusion ô£ pour des mises en page incrûˋmentales et un planificateur lance l'exûˋcution par lots de ces commandes. WebKit dispose aussi d'un minuteur qui effectue une mise en page incrûˋmentale - l'arbre est traversûˋ et les moteurs de rendu sales sont remis en page.
Les scripts qui demandent des informations sur le style, comme offsetHeight, peuvent dûˋclencher une mise en page incrûˋmentale synchrone.
La mise en page globale est gûˋnûˋralement effectuûˋe de maniû´re synchrone.
De temps en temps, la mise en page est demandûˋe par une fonction de rappel aprû´s une mise en page initiale parce que certains attributs, comme la position du dûˋfilement, ont changûˋ.
5-4. Optimisations▲
Quand une mise en page est dûˋclenchûˋe par un redimensionnement ou un changement dans la position d'un ûˋlûˋment (non dans sa taille), les dimensions des ûˋlûˋments affectûˋs ne sont pas recalculûˋes, elles sont reprises d'un cache.
Dans certains cas, seul un sous-arbre est modifiûˋ, la mise en page ne repart pas de la racine. Ceci peut arriver dans des cas oû¿ le changement est local et n'affecte pas son environnement, comme de l'insertion de texte dans des champs (sinon, chaque appui sur une touche du clavier aurait relancûˋ une mise en page depuis la racine).
5-5. Le processus de mise en page▲
La mise en page suit gûˋnûˋralement cette procûˋdure :
- L'ûˋlûˋment parent dûˋtermine sa propre largeur ;
- Le parent passe û ses enfants et :
- Place l'ûˋlûˋment enfant (il dûˋfinit ses positions en x et y),
- Appelle la mise en page de l'enfant au besoin (s'ils sont sales, si la mise en page est globale ou pour toute autre raison) ;
- Le parent utilise les hauteurs cumulûˋes de ses enfants et les hauteurs des marges internes et externes pour dûˋfinir sa propre hauteur (cette information sera utilisûˋe par le moteur de rendu de son parent) ;
- Le bit sale est mis û une valeur fausse.
Firefox utilise un objet d'ûˋtat (nsHTMLReflowState) comme paramû´tre û la mise en page (appelûˋe reflow). Entre autres, l'ûˋtat inclut la largeur du parent.
La sortie de la mise en page de Firefox est un objet de mûˋtrique (nsHTMLReflowMetrics) qui contient la hauteur calculûˋe du moteur de rendu.
5-6. Calcul de la largeur▲
La largeur d'un ûˋlûˋment est calculûˋe en utilisant la largeur du bloc conteneur, la propriûˋtûˋ width du style du moteur, les marges et bordures.
Par exemple, la largeur de l'ûˋlûˋment suivant :
<div style="width:30%"/>
serait calculûˋe par WebKit comme ceci (mûˋthode calcWidth de la classe RenderBox) :
- la largeur du contenu est le maximum de la propriûˋtûˋ availableWidth du conteneur et de zûˋro. availableWidth, dans ce cas, est la valeur calculûˋe comme :
clientWidth() - paddingLeft() - paddingRight()
- clientWidth et clientHeight reprûˋsentent l'intûˋrieur d'un objet, en dehors de sa bordure et de sa barre de dûˋfilement ;
- la largeur des ûˋlûˋments est donnûˋe par l'attribut width du style. Elle est calculûˋe comme une valeur absolue avec le pourcentage de la largeur du conteneur ;
- les bordures horizontales et les marges sont alors ajoutûˋes.
Jusqu'ici, WebKit calculait la ô¨ largeur prûˋfûˋrûˋe ô£. Il faut û prûˋsent calculer les maximum et minimum.
Si la largeur prûˋfûˋrûˋe est supûˋrieure û la largeur maximale, le maximum sera utilisûˋ. Si elle est plus petite que la largeur minimale (la plus petite unitûˋ incassable), le minimum sera utilisûˋ.
Les valeurs sont mises en cache, au cas oû¿ une mise en page serait requise sans que la largeur change.
5-7. Passage û la ligne▲
Quand un ûˋlûˋment, au beau milieu de sa mise en page, dûˋcide qu'il doit passer û la ligne, il s'arrûˆte et dit û son parent qu'il a besoin de passer û la ligne. Le parent crûˋe alors des rendus supplûˋmentaires et leur demande d'effectuer une mise en page.
6. Le dessin▲
Dans l'ûˋtape de dessin, l'arbre de rendu est parcouru et la mûˋthode ô¨ dessiner ô£ des rendus est appelûˋe pour afficher le contenu û l'ûˋcran. Le dessin utilise l'infrastructure de l'interface utilisateur.
6-1. Global et incrûˋmental▲
Comme l'affichage, le dessin peut ûˋgalement ûˆtre global, l'arbre entier est dessinûˋ, ou incrûˋmental. Dans le dessin incrûˋmental, certains rendus changent d'une faûÏon qui n'affecte pas l'arbre entier. Le rendu changûˋ invalide son rectangle sur l'ûˋcran. L'OS le voit alors comme une ô¨ rûˋgion sale ô£ et gûˋnû´re un ûˋvûˋnement de ô¨ dessin ô£. L'OS le fait intelligemment et fusionne plusieurs rûˋgions en une seule. Sous Chrome c'est un peu plus compliquûˋ, car le rendu est dans un processus diffûˋrent du processus principal. Chrome simule le comportement de l'OS dans une certaine mesure. La couche prûˋsentation ûˋcoute ces ûˋvûˋnements et dûˋlû´gue le message û la racine du rendu. L'arbre est parcouru jusqu'û ce qu'un rendu pertinent soit atteint. Il se redessinera de lui-mûˆme (et gûˋnûˋralement ses enfants avec).
6-2. L'ordre de dessin▲
CSS2 dûˋfinit l'ordre du processus de dessin. C'est en fait l'ordre dans lequel les ûˋlûˋments sont empilûˋs dans la pile des contextes. Cet ordre affecte le dessin puisque les piles sont dessinûˋes de l'arriû´re vers l'avant. L'ordre d'empilement d'un bloc de rendu est :
- Couleur d'arriû´re-plan ;
- Image d'arriû´re-plan ;
- Bordures ;
- Enfants ;
- Contour.
6-3. Liste d'affichage de Firefox▲
Firefox va au-delû de l'arbre de rendu et construit une liste d'affichage pour les rectangles dessinûˋs. Elle contient les rendus pertinents pour ces rectangles dans le bon ordre de dessin (couleur d'arriû´re-plan, puis bordures, etc.). De cette faûÏon l'arbre n'a besoin d'ûˆtre traversûˋ qu'une seule fois pour ûˆtre redessinûˋ au lieu de plusieurs, dessiner tous les arriû´res-plans, puis toutes les images, puis toutes les bordures, etc.
Firefox optimise le processus en n'ajoutant pas les ûˋlûˋments qui seront cachûˋs, comme les ûˋlûˋments placûˋs derriû´re un ûˋlûˋment opaque.
6-4. Stockage des rectangles sous Webkit▲
Avant de redessiner, Webkit stocke les anciens rectangles en bitmap. Il redessine ensuite uniquement les diffûˋrences entre les rectangles stockûˋs et les nouveaux.
7. Les changements dynamiques▲
Les navigateurs essayent de faire le moins d'actions possible en rûˋponse û un changement. Ainsi, le changement de couleur d'un ûˋlûˋment aura pour effet de seulement repeindre cet ûˋlûˋment. La modification de la position de l'ûˋlûˋment aura pour effet de repeindre cet ûˋlûˋment, ses enfants et peut-ûˆtre aussi ses frû´res et séurs. L'ajout d'un néud DOM provoquera le dessin de ce néud. Des changements majeurs, comme la taille de police de l'ûˋlûˋment html, entraûÛneront l'invalidation des caches et demanderont le rûˋarrangement et de redessin de l'arbre complet.
8. Les threads du moteur de rendu▲
Le moteur de rendu est mono thread. Presque tout, sauf l'exploitation du rûˋseau, se passe dans un seul thread. Dans Firefox et Safari c'est le thread principal du navigateur. Dans Chrome c'est le thread de processus onglet principal.
L'exploitation du rûˋseau peut ûˆtre effectuûˋe par plusieurs threads en parallû´le. Le nombre de connexions en parallû´le est limitûˋ (gûˋnûˋralement deux û six connexions. Firefox 3, par exemple, en utilise six).
8-1. La boucle de messages▲
Le thread principal du navigateur est une boucle d'ûˋvûˋnements. C'est cette boucle infinie qui rend le processus plus vivant. Il attend des ûˋvûˋnements (comme une mise en page ou les ûˋvûˋnements de dessin) et les traite. Voici le code de Firefox pour la boucle principale :
2.
while (!mExiting)
NS_ProcessNextEvent(thread);
9. Le modû´le visuel CSS2▲
9-1. La toile (canevas)▲
Selon la spûˋcification CSS2, le terme toile dûˋsigne ô¨ l'espace oû¿ la structure de format est rendue ô£, oû¿ le navigateur dessine le contenu. Les dimensions de cette toile sont infinies, mais les navigateurs choisissent une largeur initiale basûˋe sur les dimensions de la fenûˆtre.
Selon www.w3.org/TR/CSS2/zindex.html, cette toile, si elle est contenue dans une autre, est transparente sinon, elle possû´de une couleur dûˋfinie par le navigateur.
9-2. Le modû´le des boite s CSS▲
Le modû´le des boites CSS dûˋcrit des boites rectangulaires qui sont gûˋnûˋrûˋes pour les ûˋlûˋments de l'arborescence du document et prûˋsentûˋes selon le modû´le de formatage visuel.
Chaque boite contient une zone de contenu (par exemple, du texte, une image, etc.) et en option une zone de marge interne (padding), de bordure et de marge externe (margin).
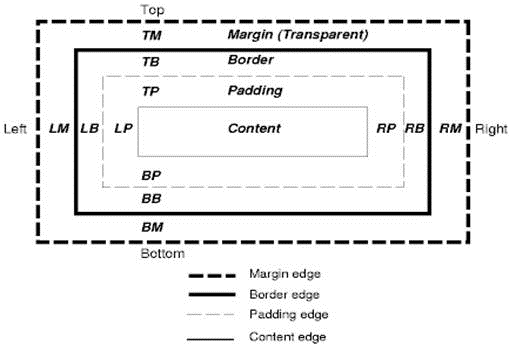
Chaque néud gûˋnû´re entre 0 et n de ces boites.
Tous les ûˋlûˋments ont une propriûˋtûˋ display qui dûˋtermine le type de boite qui sera gûˋnûˋrûˋ. Exemples :
2.
3.
block - generates a block box.
inline - generates one or more inline boxes.
none - no box is generated.
La valeur par dûˋfaut est inline, mais la feuille de style navigateur peut en configurer d'autres. Par exemple, l'affichage par dûˋfaut pour l'ûˋlûˋment div est le bloc.
Vous pouvez trouver un exemple de feuille de style par dûˋfaut ici : www.w3.org/TR/CSS2/sample.html.
9-3. Le schûˋma de positionnement▲
Il y a trois cas :
- Normal : l'objet est positionnûˋ en fonction de son emplacement dans le document, ce qui signifie que sa place dans l'arbre de rendu est comme spûˋcifiûˋ dans l'arbre DOM en fonction de son type de boite et de ses dimensions ;
- Flottant : l'objet est d'abord placûˋ comme pour un objet normal, puis dûˋplacûˋ aussi loin vers la gauche ou la droite que possible ;
- Absolu : l'objet est placûˋ dans l'arborescence de rendu diffûˋremment de sa place dans l'arbre DOM.
Le schûˋma de positionnement est dûˋfini par la propriûˋtûˋ position et l'attribut float.
- static et relative provoquent un positionnement normal ;
- absolute et fixed provoquent un positionnement absolu.
Avec un positionnement static, aucune position n'est dûˋfinie et le positionnement par dûˋfaut est utilisûˋ. Pour les autres cas, l'auteur prûˋcise la position, haut, bas, gauche, droite.
La faûÏon dont une boite est dessinûˋe est dûˋterminûˋe par :
- le type de boite ;
- les dimensions de la boite ;
- le schûˋma de positionnement ;
- des informations externes comme la taille des images et la taille de l'ûˋcran.
9-4. Les types de boites▲
Boite block : forme un bloc, elle a son propre rectangle sur la fenûˆtre du navigateur.
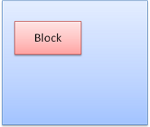
Boite inline : elle ne dispose pas de son propre bloc, mais l'intûˋrieur est un bloc conteneur.
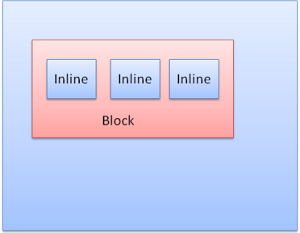
Les boites block sont mises en forme verticalement l'une aprû´s l'autre. Les boites inline sont mises en forme û l'horizontale.
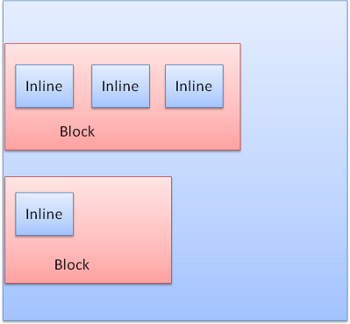
Les boites inline sont mises en ligne horizontalement, ou en ô¨boites en ligneô£. Les lignes sont au moins aussi grandes que la plus grande boite, mais peut-ûˆtre plus grandes, lorsque les boites sont alignûˋes baseline, ce qui signifie que la partie infûˋrieure d'un ûˋlûˋment est alignûˋe avec un point d'un autre bloc puis en bas. Dans le cas oû¿ la largeur du conteneur n'est pas suffisante, les boites inline seront mises sur plusieurs lignes. C'est gûˋnûˋralement ce qui se passe dans un paragraphe.
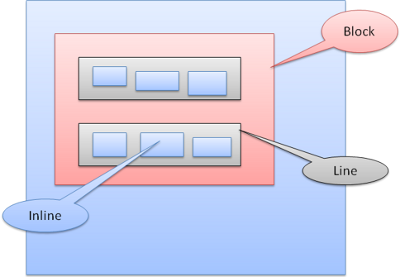
9-5. Le positionnement▲
9-5-1. Relatif▲
Le positionnement relatif : il est positionnûˋ comme d'habitude puis dûˋplacûˋ de la valeur requise.
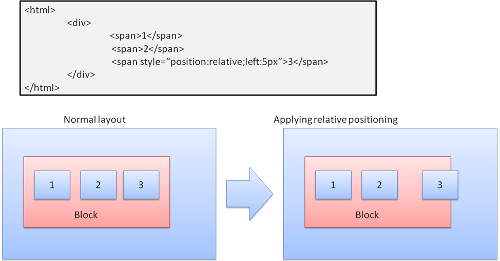
9-5-2. Flottant▲
Une boite flottante est dûˋplacûˋe vers la gauche ou vers la droite d'une ligne. La caractûˋristique û noter est que les autres boites vont s'agencer autour d'elle. Le code HTML :
Ressemblerait û :

9-5-3. Absolu et fixe▲
La mise en page est dûˋfinie exactement, quel que soit le flux normal. L'ûˋlûˋment ne participe pas au flux normal. Les dimensions sont par rapport au conteneur. Avec fixe, le conteneur est la vue du navigateur.
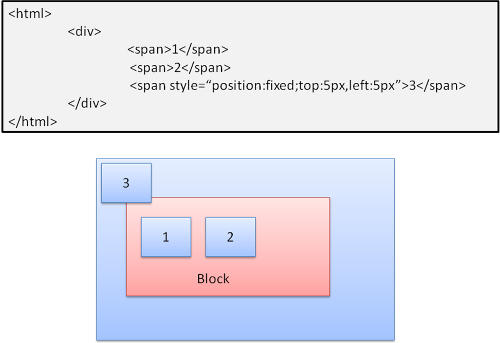
Notez, une boite fixe ne bougera pas, mûˆme quand on fait dûˋfiler le document !
9-6. La reprûˋsentation en couche▲
Elle est spûˋcifiûˋe par la propriûˋtûˋ CSS z-index. Elle reprûˋsente la troisiû´me dimension de la boite le long de ô¨ l'axe z ô£.
Les boites sont divisûˋes en piles (appelûˋ contexte d'empilement). Dans chaque pile, les ûˋlûˋments arriû´re seront dessinûˋs en premier et les ûˋlûˋments du premier plan, plus prû´s de l'utilisateur, ensuite. En cas de chevauchement l'ûˋlûˋment de premier plan permet de masquer l'ûˋlûˋment en arriû´re-plan.
Les piles sont classûˋes en fonction de la propriûˋtûˋ z-index. Les boites avec une propriûˋtûˋ z-index forment une pile locale. La fenûˆtre d'affichage prûˋsente la pile externe.
Exemple :
Le rûˋsultat sera cela :

Bien que la balise div en rouge prûˋcû´de la balise en vert, et aurait donc ûˋtûˋ peinte avant dans le flux rûˋgulier, sa propriûˋtûˋ z-index est ûˋlevûˋe, elle est donc plus en avant que la pile dûˋtenue de la boite de racine.
10. Ressources▲
- Architecture des navigateurs
- Grosskurth, Alan. A Reference Architecture for Web Browsers (pdf) ;
- Gupta, Vineet. How Browsers Work - Part 1 - Architecture.
- L'analyse
- Aho, Sethi, Ullman, Compilers: Principles, Techniques, and Tools (aka the "Dragon book"), Addison-Wesley, 1986 ;
- Rick Jelliffe. The Bold and the Beautiful: two new drafts for HTML 5.
- Firefox
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers ;
- L. David Baron, Faster HTML and CSS: Layout Engine Internals for Web Developers (Google tech talk video) ;
- L. David Baron, Mozilla's Layout Engine ;
- L. David Baron, Mozilla Style System Documentation ;
- Chris Waterson, Notes on HTML Reflow ;
- Chris Waterson, Gecko Overview ;
- Alexander Larsson, The life of an HTML HTTP request.
- Webkit
- David Hyatt, Implementing CSS(part 1) ;
- David Hyatt, An Overview of WebCore ;
- David Hyatt, WebCore Rendering ;
- David Hyatt, The FOUC Problem.
- Spûˋcifications W3C
- Instruction de compilation des navigateurs
- Firefox. https://developer.mozilla.org/en/Build_Documentation ;
- Webkit. http://webkit.org/building/build.html.
 |
Tali Garsiel est dûˋveloppeuse en Israû¨l. Elle a commencûˋ comme dûˋveloppeuse Web en 2000 et est devenue experte avec le modû´le en couche du ô¨ diable ô£ Netscape. Tout comme Richard Feynmann, elle est fascinûˋe pour comprendre comment les choses marchent et ainsi, elle a commencûˋ û creuser dans le fonctionnement interne des navigateurs et û documenter ce qu'elle a trouvûˋ. Tali a aussi publiûˋ un guide rapide au sujet des performances cûÇtûˋ client. |
10-1. Traductions▲
Cet article a ûˋtûˋ traduit en japonais, deux fois !
- How Browsers Work - Behind the Scenes of Modern Web Browsers (ja) par @_kosei ;
- ÐÐˋÐÎÐÑÐÈÐÎÐˋÐÐÐÈÐÎÍÐÐÎÐÐÛÿ¥ÿ¥ÐÂÐаWEBÐÐˋÐÎÐÑÐñХаÐÛÒÈÍÇ par @ikeike443 et @kiyoto01.
Merci û tout le monde !
10-2. Remerciements Developpez▲
Cet article est la traduction de l'article How Browsers Work: Behind the scenes of modern web browsers. Aprû´s votre lecture, 6 commentaires ![]() .
.
L'ûˋquipe de la Rûˋdaction Developpez.com remercie toutes les personnes qui ont participûˋ û cette traduction et û sa correction orthographique, avec par ordre alphabûˋtique : Bovino, ClaudeLELOUP, djibril, dourouc05, FirePrawn, ram-0000 et zoom61.
