




I. Introduction▲
Bien que les annĂŠes 2000 aient vu l'explosion de la bulle Internet et l'arrivĂŠe du Web 2.0, les standards ont peu ĂŠvoluĂŠ. Pourtant les dĂŠveloppeurs ont rĂŠussi Ă offrir de l'interactivitĂŠ avec l'utilisateur et Ă mettre Ă disposition de vĂŠritables applications sur le Web. Le W3C dĂŠfinit les applications Web comme des applications basĂŠes sur le protocole HTTP, indĂŠpendantes des plates-formes et langages d'implĂŠmentation, reposant sur des architectures Web. Elles peuvent interagir avec d'autres applications de type Web ou autres.
Le Web est devenu un lieu oÚ on peut Êchanger des informations, mais il est Êgalement devenu un marchÊ à part entière pour la vente et l'achat de biens matÊriels. Les acteurs de ce nouveau marchÊ ont besoin de sÊcuritÊ sous tous ses aspects, tels que dÊfinis par l'ANSSI (Agence Nationale de SÊcuritÊ des Systèmes d'Information)  la protection de la confidentialitÊ, de l'intÊgritÊ et de la disponibilitÊ de l'information .
Dans ce contexte, de nombreux organismes ont ĂŠtĂŠ constituĂŠs afin de lutter et de prĂŠvenir les risques liĂŠs Ă la sĂŠcuritĂŠ des informations sur le Web.
En France, l'ANSSI est une agence rattachÊe au SecrÊtaire gÊnÊral de la dÊfense et de la sÊcuritÊ nationale. Elle met à disposition des guides sur la gestion des menaces informatiques et des articles sur les recommandations et bonnes pratiques pour la sÊcuritÊ des systèmes informatiques. Le CLUSIF (Club de la SÊcuritÊ de l'Information Français) est une association d'organisations privÊes et publiques dont le but est de sensibiliser les entreprises et les collectivitÊs françaises à la sÊcuritÊ de l'information.
Aux Ătats-Unis, le Web Application Security Consortium (WASC) est une association constituĂŠe d'experts internationaux, d'industriels et d'organisations du monde Open Source, qui publie des recueils de bonnes pratiques de sĂŠcuritĂŠ pour le Web ainsi que le rapport ÂŤÂ WASC Threat Classification  qui dĂŠcrit et classe les menaces de sĂŠcuritĂŠ sur les applications Web. L'Open Web Application Security Project (OWASP) est une association de bĂŠnĂŠvoles dont l'objectif est de promouvoir la sĂŠcuritĂŠ logicielle et de sensibiliser les organisations et les personnes sur les risques liĂŠs Ă la sĂŠcuritĂŠ des applications Web. Tous les trois ans, elle publie le classement des dix failles de sĂŠcuritĂŠ les plus dangereuses dans le document ÂŤÂ OWASP Top 10 . Dans sa dernière version de 2010, la liste a ĂŠtĂŠ rĂŠĂŠvaluĂŠe afin de prendre en compte les risques et non plus le danger reprĂŠsentĂŠ par ces vulnĂŠrabilitĂŠs. En effet, les failles sont maintenant ĂŠvaluĂŠes en fonction de la facilitĂŠ Ă trouver la faille, Ă attaquer l'application Web par ce biais et du prĂŠjudice que l'attaque peut causer.
Le prÊsent document  Les principales failles de sÊcuritÊ des applications Web actuelles : principes, parades et bonnes pratiques de dÊveloppement  a pour objectif de dÊtailler chacune des failles citÊes dans le document  OWASP Top 10 . Afin de mieux les comprendre, l'architecture des applications Web sera abordÊe dans un premier temps. Dans un second temps chacune des failles sera dÊtaillÊe en expliquant l'origine du problème et en donnant des exemples-types d'attaque. Les exemples sont Êcrits pour un environnement Apache/MySQL/PHP. Puis des conseils seront donnÊs pour se protÊger de ce type d'attaque. Enfin un recueil de bonnes pratiques permettra de se prÊmunir contre la plupart des risques de sÊcuritÊ dans le dÊveloppement des applications Web.
II. Applications Web▲
II-A. Architecture▲
II-A-1. Le rĂŠseau Internet et ses protocoles▲
Le Web repose sur le rĂŠseau Internet et comme tous les rĂŠseaux informatiques, celui-ci repose sur des couches de protocoles de communication. Le paquet est l'unitĂŠ de base de la transmission de donnĂŠes sur Internet.
Shklar et R. Rosen [1] font la description suivante de la couche de protocoles pour Internet dont le couple TCP/IP est le fondement :
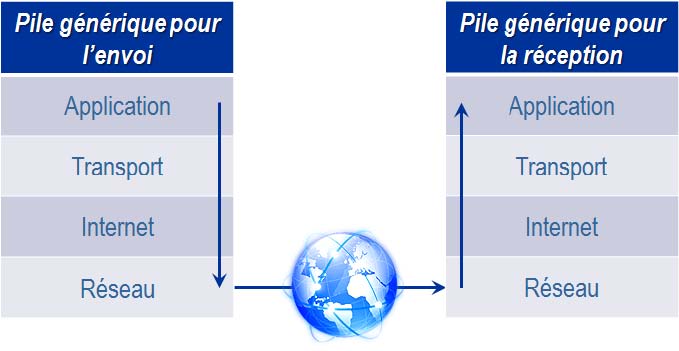
La couche  RÊseau  est la couche responsable de la transmission physique des donnÊes. Elle peut être implÊmentÊe par les lignes tÊlÊphoniques, par le GSM ou par du rÊseau Ethernet par exemple. L'information peut cheminer sur diffÊrents supports avant d'atteindre la destination.
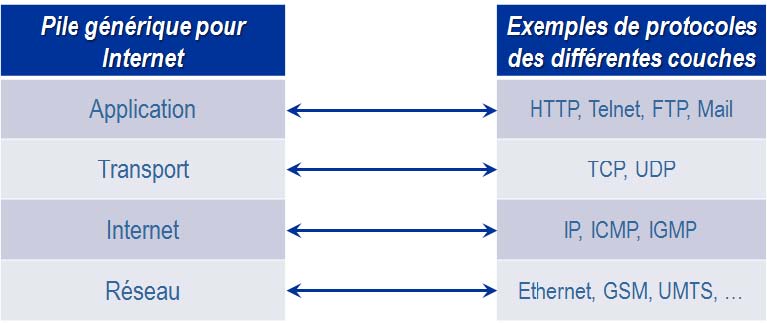
La couche  Internet  est la couche qui indique oÚ les donnÊes doivent être envoyÊes, sans garantie que la destination sera bien atteinte. Elle peut utiliser les protocoles IP (Internet Protocol) et ICMP (Internet Control Message Protocol). ICMP permet de vÊrifier que des messages peuvent être ÊchangÊs et de gÊrer les erreurs de transmission. Il est particulièrement utilisÊ par des outils tels que  ping  et  traceroute . IP est utilisÊ pour la plupart des communications sur Internet. Il prend les donnÊes issues des couches supÊrieures, dÊcrites ci-dessous, et les divise en paquets de taille prÊdÊterminÊe pour faciliter leur transmission sur le rÊseau [2]. Ainsi, si un paquet est corrompu durant la transmission, il n'est pas nÊcessaire de rÊÊmettre tout le message, mais uniquement le paquet. Chaque paquet est transmis individuellement et peut emprunter un chemin diffÊrent des autres. à l'arrivÊe la couche Internet rÊassemble l'ensemble des paquets pour reformer le message original.
La couche  Transport  repose sur deux protocoles : TCP et UDP (User Datagram Protocol). TCP s'assure que les paquets sont reçus dans le même ordre qu'ils ont ÊtÊ envoyÊs et que les paquets perdus sont à nouveau envoyÊs. TCP est donc un moyen de transmission fiable puisqu'il s'assure que les paquets sont arrivÊs. Comme indiquÊ par G.Florin et S.Natkin [3], UDP est un protocole simplifiÊ. Cela permet de transmettre des informations plus rapidement qu'avec TCP puisqu'il y a finalement moins d'informations ÊchangÊes. UDP est utilisÊ notamment par NFS (Network File System) et les applications de streaming audio et vidÊo telles que la vidÊoconfÊrence et la tÊlÊphonie sur IP oÚ la perte de paquets est acceptable et la vitesse de communication primordiale.
La couche  Application  est celle qui permet aux utilisateurs finaux de communiquer sur Internet avec des protocoles tels que Telnet, pour agir sur un serveur : FTP (File Transfer Protocol) pour la transmission de fichiers, SMTP (Simple Mail Tranfert Protocol) pour l'envoi de courrier Êlectronique et HTTP pour le Web. HTTP est un protocole de messages de type texte, basÊ sur le paradigme  requête/rÊponse . L'utilisateur envoie via son navigateur un message, la requête, au serveur HTTP. Chaque requête est traitÊe individuellement et de façon unique. Ensuite le serveur renvoie un message, la rÊponse, au navigateur. HTTP est un protocole dÊconnectÊ, c'est-à -dire que le protocole ne permet pas d'Êtablir des communications entre requêtes pour partager des informations, alors qu'une application Web a besoin de conserver les rÊponses des diffÊrentes requêtes d'un utilisateur pour avoir le même comportement qu'avec une application non Web. C'est pourquoi la plupart des navigateurs intègrent le système de  cookie  qui permet de conserver le rÊsultat d'une requête.
II-A-2. Ăvolution des architectures applicatives▲
Les applications Web ont suivi la mĂŞme ĂŠvolution que les applications plus anciennes.
La dÊcennie 1970-1980 Êtait dominÊe par le système Mainframe. Un serveur centralisait l'ensemble des informations, exÊcutait les traitements, gÊrait les droits d'accès. Le client manipulÊ par l'utilisateur permettait d'envoyer des demandes de traitement au serveur et d'en afficher les rÊsultats. La machine Êtait passive. Ce mode de fonctionnement est le même que celui du protocole HTTP. Le navigateur ne sert qu'à afficher les rÊponses HTTP.
La dÊcennie suivante 1980-1990 a vu l'Êmergence du système client/serveur. Le client rÊcupÊrait des donnÊes depuis le serveur de base de donnÊes, exÊcutait les traitements puis affichait les informations à l'Êcran et enfin mettait à jour les donnÊes sur le serveur si nÊcessaire. Le serveur ne servait plus qu'à stocker les informations et à exÊcuter Êventuellement des traitements de nuit. Cette architecture posait des problèmes de maintenance des applications sur chacun des postes utilisateur concernÊs. Les applications Web ont suivi cette Êvolution avec les  applets  au dÊbut des annÊes 90. Il s'agissait d'applications Êcrites dans un langage de dÊveloppement, exÊcutÊes par le navigateur depuis un site Web.
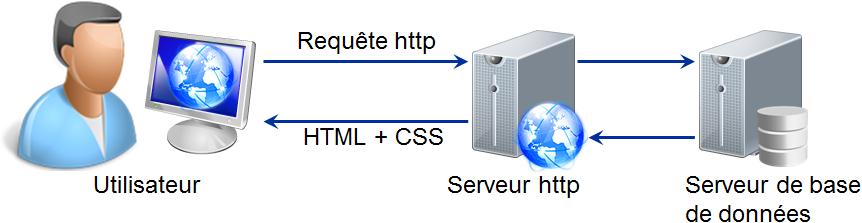
à partir des annÊes 90, les architectures Êtaient composÊes de plusieurs tiers. L'application cliente prÊsentait alors les informations à l'utilisateur et invoquait des services. Les services Êtaient responsables de l'exÊcution des processus. Les processus pouvaient être distribuÊs sur plusieurs serveurs. Enfin des serveurs Êtaient responsables du stockage des donnÊes. Dans le milieu des annÊes 90, les applications Web ont Êgalement intÊgrÊ plusieurs composants. Le navigateur Web ne s'occupe plus que de l'affichage. Le serveur HTTP pour rÊpondre aux requêtes gÊnère dynamiquement l'interface graphique dans les pages HTML en faisant appel à des services ou en interrogeant les bases de donnÊes.
Depuis les annĂŠes 2000 les applications Web et les autres types d'applications clientes peuvent utiliser les mĂŞmes services, ce qui facilite la rĂŠutilisation des dĂŠveloppements et ĂŠvite la redondance des donnĂŠes.
II-A-3. Web 2.0▲
J. Governor, D. Hinchcliffe et D. Nickull [4] expliquent que le Web 2.0 n'est pas une mise Ă jour technique, mais un changement de comportement des internautes. Comme ĂŠvoquĂŠ prĂŠcĂŠdemment, le Web avait pour but initial de mettre Ă disposition des informations. L'utilisateur ĂŠtait passif face aux sites Web. Puis le Web est devenu collaboratif, l'utilisateur est alors devenu crĂŠateur de contenu sans avoir Ă connaitre les protocoles techniques sous-jacents. L'internaute ne consulte plus l'information, il publie du contenu quel que soit le mĂŠdia (texte, vidĂŠo, musique). Internet a permis de mettre en relation des ordinateurs et est devenu le support du Web qui a permis d'y mettre Ă disposition des informations. Ă son tour le Web est devenu le support du Web 2.0 qui a permis de mettre en relation des personnes.
Ce nouveau comportement a pu naÎtre grâce à la possibilitÊ de modifier l'interface graphique sans recharger complètement la page Web. Elle devient en rÊalitÊ un conteneur dans lequel il est possible de mettre à jour et de diffÊrencier le contenu, les fonctions, selon la zone de la page.
II-B. Composants du client Web▲
II-B-1. Le navigateur▲
Dans les architectures citÊes prÊcÊdemment, le navigateur est une application cliente [2]. Il permet d'envoyer des requêtes HTTP au serveur Web et d'en interprÊter la rÊponse. Les navigateurs sont aujourd'hui capables de travailler Êgalement avec le protocole FTP et d'afficher d'autres formats tels que XML. Il existe plusieurs mÊthodes HTTP pour envoyer des requêtes au serveur. Les plus rÊpandues sont GET, HEAD et POST [1]. GET permet de demander le tÊlÊchargement du contenu d'un document, HEAD permet de n'en rÊcupÊrer que l'en-tête et POST permet d'envoyer des informations au serveur pour traitement. Lorsque l'utilisateur saisit une adresse ou clique sur un lien hypertexte, le navigateur envoie une requête GET au serveur qui ne comprend qu'un en-tête. Les requêtes POST ont un corps de message qui comporte l'ensemble des informations saisies dans un formulaire, alors qu'avec GET, ces informations sont transmises en ajoutant des paramètres à l'adresse.
HTML est un langage qui permet de dÊcrire le contenu et la structure d'une page Web. Il est composÊ d'environ 50 instructions de mise en forme. La dernière version rÊdigÊe par le W3C en 1999 est 4.01 [5]. La version 5 prÊvue pour 2012 permettra d'intÊgrer et de standardiser toutes les innovations dÊveloppÊes pour complÊter version actuelle qui ne permet pas de reprÊsenter des graphiques, de reprÊsenter une animation ou d'interagir avec l'utilisateur. Dans un document HTML, la structure de la page peut être reprÊsentÊe par un arbre appelÊ DOM (Document Object Model).
XHTML est une extension de HTML basĂŠe sur le langage structurĂŠ de description de donnĂŠes XML (eXtensible Markup Language).
CSS (Cascading Style Sheets) est un complÊment de HTML dont la version 2 actuelle a ÊtÊ dÊveloppÊe en 1998. Une feuille de style (style sheet) est un ensemble de règles à appliquer aux ÊlÊments HTML. L'utilisation de CSS permet de sÊparer les responsabilitÊs dans la prÊsentation des donnÊes à l'utilisateur. HTML peut ainsi être responsable du contenu de la page affichÊe alors que CSS sera responsable de la mise en page. En modifiant seulement le CSS, il est ainsi possible de modifier l'apparence d'une application Web. La future version CSS3 est prÊvue pour 2012.
RSS (Really Simple Syndication ou Resource description framework Site Summary) est un format simple pour la syndication de contenu. C'est un des outils identifiĂŠs comme faisant partie du Web 2.0. Il permet de centraliser des liens vers des sites en affichant pour chacun un titre et une description.
II-B-2. Les scripts▲
HTML n'offrant pas de comportement dynamique aux pages Web, les ĂŠditeurs ont crĂŠĂŠ des langages de scripts et des extensions aux navigateurs.
JavaScript est un langage de scripts inventÊ en 1995 pour le navigateur Netscape. Il permet de manipuler les objets de l'arbre DOM et de gÊrer la rÊaction à des ÊvÊnements gÊnÊrÊs par les objets de la page. Il permet en fait de modifier la page HTML sans envoyer de requête HTTP. Bien qu'il existe une norme ECMAScript gÊrÊe par l'organisme de spÊcifications ECMA, chaque navigateur a dÊveloppÊ son propre interprÊteur, ce qui pose des problèmes de portabilitÊ des applications Web.
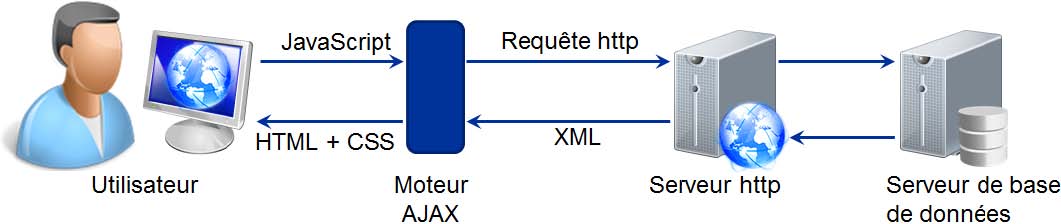
Afin de complÊter JavaScript pour permettre de modifier la page HTML affichÊe en communiquant avec le serveur HTTP, sans recharger toute la page, Microsoft a dÊveloppÊ en 2002 un nouvel objet JavaScript : XMLHttpRequest. Aujourd'hui la plupart des navigateurs intègrent cet objet. Cela permet de communiquer de manière asynchrone avec le serveur, ce que ne permet pas actuellement HTML. Ce nouvel outil a ÊtÊ la base du dÊveloppement du Web 2.0 et sera intÊgrÊ à la future norme HTML 5.
AJAX (Asynchronous Javascript And XML) est un terme inventÊ en 2005 par Jesse James Garrett. Il ne s'agit pas d'une nouvelle technologie, mais d'une façon d'utiliser conjointement les technologies XHTML, JavaScript et CSS. Les applications Web dÊveloppÊes selon le paradigme Ajax utilisent massivement les requêtes GET pour mettre à jour l'interface graphique.
Des ĂŠditeurs tels que Macromedia et Microsoft ont ĂŠgalement dĂŠveloppĂŠ des extensions (plugin) aux navigateurs comme Flash et Silverlight pour offrir des interfaces plus riches. Comme le prĂŠsent document ne traitera pas les failles de sĂŠcuritĂŠ de ces composants, ils ne seront pas plus amplement dĂŠtaillĂŠs.
II-C. Composants serveur▲
II-C-1. Serveurs Web et serveurs d'application▲
Comme ĂŠvoquĂŠ prĂŠcĂŠdemment, le navigateur et le serveur communiquent en utilisant le protocole HTTP. Les serveurs ne sont pas obligĂŠs d'implĂŠmenter toutes les mĂŠthodes HTTP, seulement GET et HEAD. Bien qu'optionnelle, peu de serveurs actuels n'implĂŠmentent pas la mĂŠthode POST.
Sur Internet le navigateur et le serveur HTTP communiquent rarement directement. Le plus souvent un serveur intermÊdiaire est prÊsent : le serveur proxy. Les requêtes à destination du serveur sont interceptÊes par le serveur proxy qui peut leur faire subir un traitement, avant de les retransmettre au serveur. Ce principe est Êgalement appliquÊ aux rÊponses. Le serveur proxy peut servir de cache pour moins solliciter le serveur HTTP. Il est possible de faire agir plusieurs serveurs proxy en cascade.
La seule fonction du serveur Web Êtant d'envoyer le contenu des fichiers au client, des extensions peuvent y être ajoutÊes, permettant de faire appel à des services pour gÊnÊrer dynamiquement les informations à transmettre. Ils traitent les requêtes HTTP que le serveur HTTP leur a fait suivre, interprètent et exÊcutent le code de l'application, puis gÊnèrent une rÊponse qu'ils renvoient au serveur HTTP qui l'enverra au navigateur de l'utilisateur. Si ces services fonctionnent indÊpendamment du serveur HTTP, ils sont appelÊs serveurs d'applications.
L'extension CGI (Common Gateway Interface) permet l'exÊcution d'un programme extÊrieur appelÊ  gateway  dont la sortie standard d'affichage sera renvoyÊe au client par le serveur HTTP. Le langage utilisÊ pour le dÊveloppement du programme n'a pas d'importance. Cela peut être du C++, du Perl ou même Java. Il faut seulement que le programme puisse être exÊcutÊ sur la machine hÊbergeant le serveur HTTP.
De mĂŞme que CGI, l'extension Java Servlet dĂŠveloppĂŠe par Sun permet d'intercepter les requĂŞtes, de gĂŠnĂŠrer les rĂŠponses pour exĂŠcuter des applications Java. La diffĂŠrence est que la machine virtuelle Java peut ĂŞtre lancĂŠe sur un serveur diffĂŠrent du serveur HTTP. Cette extension permet de conserver des informations entre les requĂŞtes.
JSP (Java Server Pages) est un langage qui permet d'insĂŠrer des blocs de script basĂŠs sur Java dans un contenu HTML. Les pages JSP sont interprĂŠtĂŠes et transformĂŠes en Servlet par un serveur d'application pour ĂŞtre exĂŠcutĂŠes.
ASP (Active Server Pages) est le concurrent de JSP dĂŠveloppĂŠ par Microsoft. Ătant basĂŠ sur le langage VBScript, ASP est devenu très populaire dans le milieu des dĂŠveloppeurs Visual-Basic dont il est très proche. Tout comme JSP, ASP permet d'insĂŠrer des blocs de script dans du contenu HTML. Pour combler les lacunes d'ASP, Microsoft a dĂŠveloppĂŠ la plate-forme ÂŤÂ .NET  qui permet d'utiliser les autres langages de dĂŠveloppement du monde Microsoft, tel que C#, pour la gĂŠnĂŠration dynamique de contenu HTML. L'exĂŠcution de code ASP ou .Net est limitĂŠe aux serveurs Windows.
PHP (sigle rÊcursif pour  PHP: Hypertext Preprocessor ) est un langage proche de Perl et des scripts Shell, ce qui a fait son succès auprès de la communautÊ du monde Unix. C'est ce langage qui sera utilisÊ pour les exemples du prÊsent document.
II-C-2. Serveurs de donnĂŠes▲
Les donnÊes Êtant principalement gÊrÊes par des serveurs dÊdiÊs, les langages citÊs prÊcÊdemment offrent des moyens d'interagir avec eux. Les systèmes de gestion de bases de donnÊes permettent d'interroger les donnÊes et de les mettre à jour. Le langage le plus rÊpandu est SQL (Structured Query Language) pour les bases de donnÊes relationnelles. La base de donnÊes MySQL sera le moteur relationnel utilisÊ pour les exemples du prÊsent document. Le Web 2.0 a apportÊ de nouveaux besoins auxquels le modèle relationnel ne peut pas rÊpondre. Les modèles NoSQL (Not Only SQL) ont alors pu Êmerger.
Les informations sur les personnes et ressources ainsi que les informations nÊcessaires à l'authentification peuvent être stockÊes et gÊrÊes par des annuaires LDAP (Lightweight Directory Access Protocol). Il s'agit d'un service qui peut être interrogÊ par le protocole LDAP de la couche  Application .
Les services Web sont des applications Web dont le but est de fournir des donnĂŠes selon une structure prĂŠdĂŠfinie et des services Ă une autre application en utilisant les protocoles standards d'Internet.
III. Failles de SĂŠcuritĂŠ▲
III-A. Menaces et risques applicatifs▲
III-A-1. Types d'attaques▲
Le WASC Êtablit dans son rapport  WASC Threat Classification  une liste exhaustive des menaces qui pèsent sur la sÊcuritÊ des applications Web. Elles sont regroupÊes en six catÊgories dÊfinies dans la version 2004 de ce rapport.
La catÊgorie  authentification  regroupe les attaques de sites Web dont la cible est le système de validation de l'identitÊ d'un utilisateur, d'un service ou d'une application.
La catÊgorie  autorisation  couvre l'ensemble des attaques de sites Web dont la cible est le système de vÊrification des droits d'un utilisateur, d'un service ou d'une application pour effectuer une action dans l'application.
La catÊgorie  attaques côtÊ client  rassemble les attaques visant l'utilisateur pendant qu'il utilise l'application.
La catÊgorie  exÊcution de commandes  englobe toutes les attaques qui permettent d'exÊcuter des commandes sur un des composants de l'architecture du site Web.
La catÊgorie  rÊvÊlation d'informations  dÊfinit l'ensemble des attaques permettant de dÊcouvrir des informations ou des fonctionnalitÊs cachÊes.
La catĂŠgorie ÂŤÂ attaques logiques  caractĂŠrise les attaques qui utilisent les processus applicatifs (système de changement de mot de passe, système de crĂŠation de compteâŚ) Ă des fins hostiles.
III-A-2. Risques de sĂŠcuritĂŠ▲
Contrairement au WASC qui dĂŠcrit toutes les attaques possibles sur une application Web, l'OWASP ne traite que les dix plus grands risques de sĂŠcuritĂŠ. Le rapport ÂŤÂ OWASP Top 10Â Âť permet ainsi Ă l'ĂŠquipe projet de se focaliser sur la protection de l'application Web face aux menaces les plus importantes, ce qui est moins coĂťteux et plus facilement rĂŠalisable que d'essayer de se protĂŠger de tous les dangers. L'OWASP ĂŠtablit le classement 2010 ci-dessous, dont chacune des failles est dĂŠveloppĂŠe dans les chapitres suivants.
Une faille d'injection se produit quand une donnĂŠe non fiable est envoyĂŠe Ă un interprĂŠteur en tant qu'ĂŠlĂŠment d'une commande ou d'une requĂŞte. Les donnĂŠes hostiles de l'attaquant peuvent duper l'interprĂŠteur afin de l'amener Ă exĂŠcuter des commandes inhabituelles ou Ă accĂŠder Ă des donnĂŠes non autorisĂŠes.
Les failles de Cross-Site Scripting (XSS) se produisent chaque fois qu'une application prend des donnĂŠes non fiables et les envoie Ă un navigateur Web sans validation. XSS permet Ă des attaquants d'exĂŠcuter du script dans le navigateur de la victime afin de dĂŠtourner des sessions utilisateur, dĂŠfigurer des sites Web, ou rediriger l'utilisateur vers des sites malveillants.
Les failles de violation de gestion d'authentification et de session se produisent quand les fonctions correspondantes ne sont pas mises en Ĺuvre correctement, permettant aux attaquants de compromettre les mots de passe, clĂŠs, jetons de session, ou d'exploiter d'autres failles d'implĂŠmentation pour s'approprier les identitĂŠs d'autres utilisateurs.
Une faille de rÊfÊrence directe à un objet se produit quand un dÊveloppeur expose une rÊfÊrence à une variable interne, tels un nom de fichier, de dossier, un enregistrement de base de donnÊes ou une clÊ de base de donnÊes. Sans un contrôle d'accès ou autre protection, les attaquants peuvent manipuler ces rÊfÊrences pour accÊder à des donnÊes non autorisÊes.
Une attaque par falsification de requĂŞte intersite (CSRF) force le navigateur d'une victime authentifiĂŠe Ă envoyer une requĂŞte HTTP, comprenant le cookie de session de la victime ainsi que toute autre information automatiquement incluse, Ă une application Web vulnĂŠrable. Ceci permet Ă l'attaquant de forcer le navigateur de la victime Ă gĂŠnĂŠrer des requĂŞtes, l'application vulnĂŠrable considĂŠrant alors qu'elles ĂŠmanent lĂŠgitimement de la victime.
Une faille due Ă une mauvaise configuration de sĂŠcuritĂŠ se produit quand les serveurs d'application, serveurs Web, serveur de base de donnĂŠes, et la plate-forme n'ont pas de configuration sĂŠcurisĂŠe correctement ĂŠtablie et dĂŠployĂŠe. Tous ces paramètres doivent ĂŞtre dĂŠfinis, mis en Ĺuvre, et maintenus. Ceci implique de maintenir tous les logiciels Ă jour, notamment toutes les bibliothèques de code employĂŠes par l'application.
Une faille de stockage de donnÊes non sÊcurisÊes se produit quand une application Web ne protège pas correctement les donnÊes sensibles, telles que les numÊros de cartes de crÊdit, de sÊcuritÊ sociale, les informations d'authentification, avec un algorithme de chiffrement ou de hash appropriÊ. Les pirates peuvent voler ou modifier ces donnÊes faiblement protÊgÊes pour perpÊtrer un vol d'identitÊ et d'autres crimes, tels que la fraude à la carte de crÊdit.
La dÊfaillance dans la restriction des accès à une URL se produit quand une application Web ne protège pas l'accès aux URL. Les applications doivent effectuer des contrôles d'accès similaires chaque fois que ces pages sont accÊdÊes, sinon les attaquants seront en mesure de forger des URL pour accÊder à ces pages cachÊes.
La faille de protection de la couche transport se produit quand les applications ne peuvent pas chiffrer et protĂŠger la confidentialitĂŠ et l'intĂŠgritĂŠ du trafic rĂŠseau sensible. De plus, quand elles le font, elles supportent parfois des algorithmes faibles, utilisent des certificats expirĂŠs ou invalides, ou ne les emploient pas correctement.
Une faille de redirection et renvoi non validĂŠs se produit quand une application Web rĂŠoriente les utilisateurs vers d'autres pages et sites Web, et utilise des donnĂŠes non fiables pour dĂŠterminer les pages de destination. Sans validation appropriĂŠe, les attaquants peuvent rediriger les victimes vers des sites de phishing ou de logiciel malveillant, ou utiliser les renvois pour accĂŠder Ă des pages non autorisĂŠes.
III-A-3. Correspondances entre les dĂŠfinitions de l'OWASP et du WASC▲
Le tableau ci-dessous fait le lien entre les catĂŠgories et les attaques dĂŠfinies par le WASC dans le rapport de 2010 et les menaces identifiĂŠes par l'OWASP dans le classement de 2010.
|
Risques identifiĂŠs par l'OWASP en 2010 |
Attaques identifiĂŠes par le WASC en 2010 |
CatĂŠgories |
|---|---|---|
|
Injection |
SQL Injection (WASC-19) |
ExĂŠcution de commandes |
|
Cross-Site Scripting |
Cross-Site Scripting (WASC-08) |
Attaques cĂ´tĂŠ client |
|
Violation de Gestion d'Authentification et de Session |
Insufficient Authentication (WASC-01) |
Autorisation, authentification |
|
RĂŠfĂŠrence directe Ă un objet non sĂŠcurisĂŠe |
Insufficient Authentication (WASC-01) |
Autorisation, authentification, rĂŠvĂŠlation d'informations |
|
Falsification de requĂŞtes intersites |
Cross-Site Request Forgery (WASC-09) |
Attaques logiques |
|
Gestion de configuration non sĂŠcurisĂŠe |
Server Misconfiguration (WASC-14) |
RĂŠvĂŠlation d'informations |
|
Stockage de donnĂŠes non sĂŠcurisĂŠ |
Insufficient Data Protection (WASC-50) |
RĂŠvĂŠlation d'informations |
|
DÊfaillance de restriction d'accès à une URL |
Insufficient Authorization (WASC-02) |
Autorisation, authentification, rĂŠvĂŠlation d'informations |
|
Communications non sĂŠcurisĂŠes |
Insufficient Transport Layer Protection (WASC-04) |
RĂŠvĂŠlation d'informations |
|
Redirection et renvoi non validĂŠs |
URL Redirector Abuse (WASC-38) |
Attaques logiques |
III-B. Injection▲
III-B-1. Principe▲
L'attaque par injection est ÊvaluÊe par l'OWASP comme Êtant la plus risquÊe, car la faille est assez rÊpandue, il est facile de l'exploiter et l'impact peut être très important. Cela va de la simple rÊcupÊration de donnÊes à la prise totale de contrôle du serveur. La victime de l'attaque est un des composants techniques de l'application Web.
Contensin [6] explique que pour rĂŠaliser une attaque de ce type, il faut injecter dans les zones de saisie classiques prĂŠsentĂŠes Ă l'utilisateur du code malicieux. Ces donnĂŠes seront interprĂŠtĂŠes comme des instructions par un des composants de l'application Web. Les champs de formulaires peuvent ĂŞtre protĂŠgĂŠs par JavaScript pour vĂŠrifier que les valeurs saisies correspondent Ă ce qui est attendu. Cependant, J. Scambray, V. Liu et C. Sima [7] dĂŠmontrent qu'il est possible d'outrepasser ces vĂŠrifications en faisant appel Ă un serveur proxy personnel, par exemple, qui permettra d'intercepter les requĂŞtes pour les modifier et envoyer le code malicieux. La difficultĂŠ de l'attaque rĂŠside finalement dans la dĂŠtection des technologies utilisĂŠes pour formuler le code d'attaque adĂŠquat. Cependant, la plupart des applications Web de gestion de contenu prĂŠsentes sur le Web sont basĂŠes sur des projets Open Source. H. Dwivedi, A. Stamos, Z. Lackey et R. Cannings [8] montrent qu'il est alors facile d'identifier les technologies employĂŠes en parcourant le code source mis Ă disposition. De plus, il existe des outils d'injection automatique disponibles sur le Web, rendant le risque plus ĂŠlevĂŠ. L'exploitation de la faille devient automatisable.
III-B-2. Exemples d'attaque▲
L'attaque par injection SQL consiste à injecter du code SQL qui sera interprÊtÊ par le moteur de base de donnÊes. Le code malicieux le plus rÊpandu est d'ajouter une instruction pour faire en sorte que la requête sous-jacente soit toujours positive. Cela permet par exemple d'usurper une identitÊ pour se connecter à une application Web, de rendre l'application inutilisable ou de supprimer toutes les donnÊes de la table visÊe, voire de la base de donnÊes complète. L'exemple suivant va interroger une table qui contient la liste des cartes bancaires enregistrÊes dans la base de donnÊes de l'application Web d'un site marchand. Le script de crÊation de cette table est le suivant :
CREATE TABLE IF NOT EXISTS `comptes` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'identifiant',
`nom` varchar(30) NOT NULL COMMENT 'nom d''utilisateur',
`motdepasse` varchar(41) NOT NULL,
`typecarte` varchar(30) NOT NULL COMMENT 'type de carte',
`numerocarte` varchar(30) NOT NULL COMMENT 'numĂŠro de carte',
PRIMARY KEY (`id`),
UNIQUE KEY `nom` (`nom`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=5 ;Pour afficher le numÊro de carte bancaire, l'utilisateur doit s'authentifier. La requête SQL suivante permet de vÊrifier que le couple utilisateur  user4 /mot de passe du compte  eng111  est correct et si tel est le cas renvoie le numÊro de carte bancaire :
SELECT `numerocarte`
FROM `comptes`
WHERE `nom` = 'user4'
AND `motdepasse` = PASSWORD( 'eng111' )Le script PHP pour exploiter cette requête de façon dynamique avec les informations fournies par l'utilisateur est le suivant :
<?php //connexion a la base de donnees
mysql_connect('localhost', 'root', '');
mysql_select_db('eng111');
//recuperation des parametres
$nom = $_GET['nom'];
$motdepasse = $_GET['motdepasse'];
//generation de la requete
$requeteSQL = "SELECT numerocarte FROM comptes WHERE nom = '$nom' AND motdepasse = PASSWORD( '$motdepasse' )";
//execution de la requete
$reponse = mysql_query($requeteSQL);
$resultat = mysql_fetch_assoc($reponse);
//affichage du resultat
echo $resultat['numerocarte'];
?>En remplissant le formulaire avec la valeur  ' OR 1=1 -- '  pour le champ  nom  et n'importe quelle valeur pour le mot de passe, la requête qui sera envoyÊe à la base de donnÊes devient :
SELECT numerocarte FROM comptes WHERE nom = '' OR 1=1 -- '' AND motdepasse = PASSWORD( 'x' )Ainsi la condition 1=1 est toujours vÊrifiÊe et le reste de la commande est mis en commentaire grâce à la chaÎne de caractères  -- . Cela permet donc de rÊcupÊrer alÊatoirement un numÊro de carte.
L'attaque par injection de XPath suit le mĂŞme principe que pour SQL [9]. En effet, XPath est un langage de requĂŞte pour gĂŠrer les donnĂŠes stockĂŠes au format XML, comme le fait SQL pour les bases de donnĂŠes relationnelles. XPath et Xquery, dont XPath est un sous-ensemble, souffrent donc des mĂŞmes vulnĂŠrabilitĂŠs face Ă l'injection de code malicieux.
L'attaque par injection LDAP permet d'accĂŠder Ă des informations privĂŠes qui sont enregistrĂŠes dans l'annuaire d'entreprise. En modifiant le comportement du filtrage dans la requĂŞte LDAP qui sera gĂŠnĂŠrĂŠe, il est possible de rĂŠcupĂŠrer la liste exhaustive des adresses de courrier ĂŠlectronique d'une entreprise pour les saturer de spam par exemple.
L'attaque par injection de commandes est surtout principalement possible sur les scripts CGI Êcrits en Perl, PHP et Shell. Il est possible de prendre le contrôle du serveur. Il faut pour cela faire en sorte que la commande initiale soit exÊcutÊe sans problème et ajouter des commandes du système d'exploitation du serveur qui seront exÊcutÊes par le serveur.
L'attaque par traversÊe de rÊpertoire permet d'accÊder à des fichiers prÊsents sur le serveur. Les fichiers cibles privilÊgiÊs Êtant ceux contenant des informations de sÊcuritÊ comme le fichier des mots de passe ou les fichiers contenant les clÊs privÊes de chiffrement pour SSL par exemple. Cette attaque est rendue possible si l'application Web inclut du contenu de fichier en passant l'adresse de ce fichier en paramètres de la requête.
Les attaques XXE (XML eXternal Entity) sont un dÊrivÊ des attaques par traversÊe de rÊpertoire. Les consÊquences vis-à -vis des fichiers prÊsents sur les serveurs sont donc les mêmes. Ce type d'attaque est basÊ sur la fonctionnalitÊ de XML  entitÊs externes . Les entitÊs sont des substituts pour des sÊquences d'information. Elles sont Êquivalentes aux variables dans les langages de programmation. Les entitÊs externes permettent de dÊclarer des documents dont le contenu sera affichÊ lors de l'utilisation de l'entitÊ. Si l'entitÊ pointe sur un fichier existant sur le serveur, son contenu pourra être divulguÊ à l'attaquant. Cette fonctionnalitÊ peut être exploitÊe en plaçant un fichier XML au format RSS sur un site et de l'intÊgrer à un agrÊgateur en ligne. Si ce dernier est vulnÊrable, il sera alors possible de voir le contenu des fichiers demandÊs par l'attaquant.
III-B-3. Parade et bonnes pratiques▲
Les diffÊrentes attaques citÊes prÊcÊdemment reposent principalement sur l'utilisation de caractères spÊcifiques qui permettent de mettre en commentaire des portions de code et d'insÊrer du code frauduleux. Il est cependant rare que l'application ait besoin d'accepter les caractères suivants :
& ~ " # ' { } ( [ ] ( ) - | ` _ \ ^ @ \ * / . < > , ; : ! $Cependant les applications Web de gestion de contenu comme les forums doivent les accepter, notamment les forums utilisÊs par les dÊveloppeurs pour partager du code. Dans ce cas, il faut transformer au moins les caractères ci-dessus en code HTML avant de les stocker dans la base de donnÊes. L'affichage de l'information ne sera pas diffÊrent pour l'utilisateur, mais les donnÊes seront plus sÝres.
Bien qu'un site puisse subir diffÊrents types d'attaques par injection, il suffit de vÊrifier que les caractères utilisÊs sont ceux attendus. Ce contrôle doit être effectuÊ au niveau du client grâce à JavaScript et au niveau du serveur lorsque les paramètres sont rÊcupÊrÊs pour fermer la faille de sÊcuritÊ. Par exemple, le langage PHP offre une fonctionnalitÊ qui permet de transformer ces caractères.
<?php
$nouvelleValeur=htmlspecialchars($valeurParametre,ENT_QUOTES);
?>De plus il faut vĂŠrifier que les valeurs sont bien du type et du format attendus (longueur, intervalle de valeurâŚ).
L'ANSSI porte une attention particulière aux outils automatiques d'exploitation des failles SQL dans son bulletin de sÊcuritÊ CERTA-2011-ACT-045. Pour dÊterminer si un site est victime de ce type d'agression, il faut vÊrifier dans les journaux d'activitÊ du serveur HTTP qu'il n'y a pas d'ÊvÊnement inhabituel, tel qu'un nombre de requêtes HTTP anormalement ÊlevÊ ou des requêtes ayant pour paramètres des valeurs inappropriÊes.
III-C. Cross-Site Scripting (XSS)▲
III-C-1. Principe▲
L'OWASP considère la vulnÊrabilitÊ à XSS comme une faille critique, car elle est très rÊpandue et facile à dÊtecter. Les attaques s'appuient principalement sur les formulaires des applications Web. Les victimes sont les utilisateurs des applications Web vulnÊrables. L'ANSSI signale dans la note d'information CERTA-2002-INF-001-001 que les scripts frauduleux peuvent endommager la base de registre de la victime, afficher des formulaires dont les saisies seront envoyÊes à l'attaquant, rÊcupÊrer les cookies prÊsents sur la machine de la victime, exÊcuter des commandes systèmes et construire des liens dÊguisÊs vers des sites malveillants.
Y.-W. Huang, C.-H. Tsai, T.-P. Lin, S.-K. H., D.T. Lee et S.-Y. Kuo [10] indiquent que l'attaque XSS est ĂŠgalement une attaque par injection, car l'objectif de l'attaquant est de soumettre un code frauduleux Ă l'application. A. Kiezun, P. J. Guo, K. Jayaraman, M. D. Ernst [11] montrent qu'il existe en fait deux types d'attaques XSS.
L'attaque XSS par rÊflexion (reflected XSS) s'appuie sur le fait que l'application Web affiche ce que l'utilisateur vient de saisir dans un formulaire dans une page de rÊsultat. Le navigateur de la victime exÊcute alors le code frauduleux gÊnÊrÊ dans la page de rÊsultat. Tous les champs de formulaire sont donc une faille de sÊcuritÊ potentielle que l'attaquant peut exploiter par XSS. L'attaquant crÊe un lien dÊguisÊ vers l'application Web dont un des paramètres contient du code JavaScript frauduleux. En utilisant ce lien, la victime fait exÊcuter par son navigateur le code JavaScript. Le Web 2.0 et ses systèmes de gestion de contenu ont popularisÊ cette attaque en permettant de publier des liens aisÊment et visibles sur tout le Web.
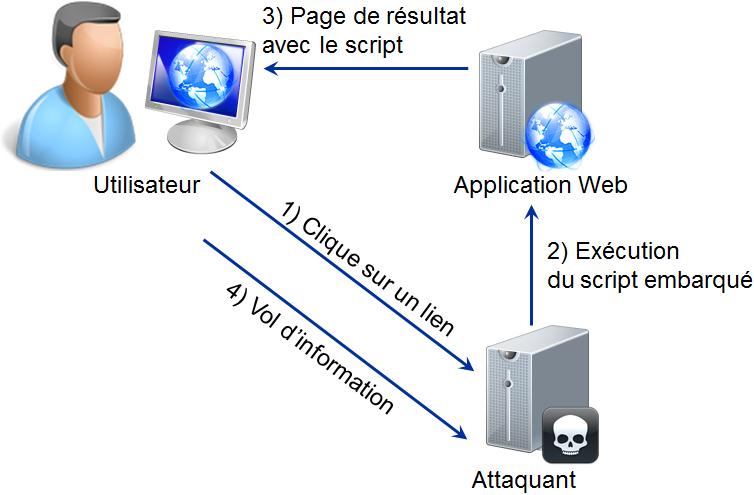
L'attaque XSS stockÊe (stored XSS) s'appuie sur le fait que l'attaquant rÊussisse à stocker dans la base de donnÊes du code frauduleux qui sera exÊcutÊ par la victime lorsqu'elle tentera d'afficher la donnÊe malveillante. Cette attaque est plus dangereuse que la première, car le code fait partie intÊgrante des donnÊes de l'application Web et peut atteindre plusieurs victimes.
III-C-2. Exemples d'attaque▲
L'attaque XSS par rĂŠflexion peut ĂŞtre implĂŠmentĂŠe par diffĂŠrents moyens.
Le plus facile est d'utiliser un moteur de recherche vulnÊrable. Par exemple les outils de forum intègrent des formulaires pour recherche des messages par leur contenu. La page de rÊsultat reprend gÊnÊralement les mots-clÊs saisis. Il suffit alors de mettre comme paramètre de recherche un code JavaScript qui sera ensuite interprÊtÊ par le navigateur de la victime. Pour rÊaliser cette attaque, il suffit de laisser un lien qui aura pour paramètre le code malveillant.
http://www.forum-vulnĂŠrable.com/recherche.php?parametre=<script>alert(‘attaque XSS')</script>En cliquant sur ce lien, la victime lancera la recherche. Puis le moteur de recherche affichera le paramètre ÂŤÂ <script>alert(âattaque XSS')</script>  qui sera exĂŠcutĂŠ par le navigateur.
Des applications Web sont responsables de l'affichage des courriers Êlectroniques : les webmails. Pour consulter son courrier, l'utilisateur va prÊalablement s'authentifier et ses informations d'identification seront stockÊes dans des cookies. Un courrier malveillant peut intÊgrer du code JavaScript qui sera interprÊtÊ par le navigateur. Ce code sera capable de rÊcupÊrer les cookies et envoyer les informations à l'attaquant.
L'attaque XSS stockÊe injecte du code malveillant dans la base de donnÊes. L'application Web suivante de type forum va permettre d'illustrer cette attaque. La table support de la dÊmonstration est la suivante :
CREATE TABLE IF NOT EXISTS `messages` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'identifiant',
`numerosujet` int(11) NOT NULL COMMENT 'numero du sujet',
`redacteur` varchar(30) NOT NULL COMMENT 'nom du redacteur du message', `message` varchar(4000) NOT NULL COMMENT 'contenu du message',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=latin1 AUTO_INCREMENT=6 ;Le script PHP suivant est responsable de l'enregistrement d'un message. Comme une des informations saisies (le nom du rĂŠdacteur) est rĂŠaffichĂŠe, cela implique que ce code est vulnĂŠrable Ă une attaque XSS par rĂŠflexion.
<?php
//recuperation des parametres
$message=$_GET['message'];
$nom=$_GET['nom'];
$numsujet=$_GET['numsujet'];
//generation de la requete
$requeteSQL = "INSERT INTO messages VALUES (NULL, '$numsujet', '$nom', '$message')";
//execution de la requete
$reponse = mysql_query($requeteSQL);
//affichage du resultat
echo "<tr><td> </td><td>Merci $nom de votre participation. Vous venez de saisir : $message</td></tr>";
?>En saisissant comme message un code JavaScript malveillant, il sera enregistrĂŠ dans la base de donnĂŠes.
Le script PHP suivant est responsable de l'affichage de l'ensemble des messages d'un sujet.
<?php
//recuperation des parametres
$numsujet=$_GET['searchsujet'];
//generation de la requete
$requeteSQL = "SELECT * FROM messages WHERE numerosujet=$numsujet order by id";
//execution de la requete
$reponse = mysql_query($requeteSQL);
//affichage du resultat
echo "<tr><td> Sujet $numsujet</td><td>";
while($resultat = mysql_fetch_assoc($reponse)) {
echo $resultat['redacteur'] . " : " . $resultat['message'] . "<br>";
}
echo "</td></tr>";
?>Lorsque des utilisateurs afficheront le fil des messages, le message frauduleux sera automatiquement envoyĂŠ aux navigateurs et interprĂŠtĂŠ crĂŠant une attaque XSS.
III-C-3. Parade et bonnes pratiques▲
Les recommandations faites prÊcÊdemment pour se prÊmunir des risques d'injection sont valables pour XSS. Cependant, transformer les six caractères douteux suivants suffit.
&  &
<  <
>  >
"  "
'  ' (' n'est pas recommandĂŠ)
/  /CĂ´tĂŠ client avec JavaScript il faut vĂŠrifier les donnĂŠes saisies par les utilisateurs. CĂ´tĂŠ serveur, il faut vĂŠrifier les donnĂŠes rĂŠcupĂŠrĂŠes en paramètre. Il faut rejeter toutes les donnĂŠes qui ne sont pas conformes Ă ce qui est attendu.
Pour Êviter le vol de cookies par du code JavaScript, il est possible de positionner l'attribut de cookie HTTPOnly [8]. S'il est prÊsent, le navigateur interdit au moteur JavaScript de lire ou Êcrire dans les cookies. Cet attribut est très peu utilisÊ par les applications Web, car tous les navigateurs ne le gèrent pas. Cependant il est prÊfÊrable de l'utiliser, car les navigateurs les plus populaires l'implÊmentent, ce qui diminue les risques liÊs aux cookies.
<?php
session.cookie_httponly = True
?>Les navigateurs intègrent des protections contre XSS en interdisant l'exÊcution de code JavaScript qui modifie une page Web depuis une page Web ne portant pas le même nom de domaine.
III-D. Violation de gestion d'authentification et de session▲
III-D-1. Principe▲
Cette faille de sÊcuritÊ regroupe toutes les vulnÊrabilitÊs pouvant mener à une usurpation d'identitÊ. Ces points de faiblesse dans les applications Web peuvent ouvrir à des attaquants des accès à des fonctionnalitÊs des applications Web auxquelles ils n'ont pas le droit normalement. Cela peut donc leur permettre de voler des informations ou d'endommager le bon fonctionnement de l'application. La protection des accès à l'application repose gÊnÊralement sur un système d'authentification. La plupart du temps, le système d'authentification est redÊveloppÊ pour chaque application, ce qui implique que ces systèmes ne bÊnÊficient pas de l'expÊrience acquise sur le dÊveloppement d'autres applications.
Pour comprendre comment les attaques peuvent être menÊes, il faut comprendre le mÊcanisme d'authentification le plus commun des applications Web :
- L'utilisateur non authentifiÊ demande l'accès à une page Web ;
- Le serveur renvoie une page d'authentification ;
- L'utilisateur remplit le formulaire en fournissant un identifiant et un mot de passe et revoie ces informations au serveur Web ;
- Le serveur Web fait appel à un service pour vÊrifier la validitÊ du couple identifiant/mot de passe ;
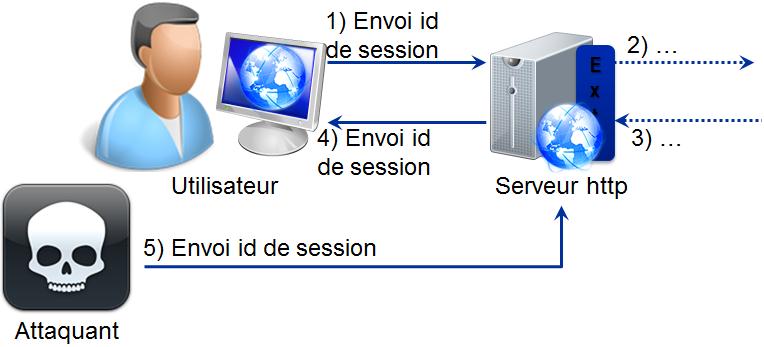
- Si la validitÊ est avÊrÊe, le serveur Web fournit un identifiant de session à l'utilisateur. Comme expliquÊ prÊcÊdemment HTTP est un protocole dÊconnectÊ, donc entre deux requêtes HTTP la connexion entre le navigateur et le serveur HTTP est coupÊe. Donc le serveur HTTP ne peut pas reconnaÎtre un utilisateur qui s'est dÊjà authentifiÊ et qui a ouvert une session de travail dans l'application Web. Pour remÊdier à cela, la plupart des systèmes d'authentification reposent sur un identifiant de session. Celui-ci est envoyÊ à chaque page entre le client et le serveur par le biais d'un cookie, d'un paramètre d'adresse ou d'un champ de formulaire invisible pour l'utilisateur ;
- L'utilisateur peut utiliser l'application Web tant que la session est ouverte.
Les attaques pour usurper une identitÊ peuvent être regroupÊes en deux catÊgories :
- les attaques contre le système d'authentification qui cherchent à obtenir un droit d'accès ;
- les usurpations de session qui permettent de s'affranchir de l'ĂŠtape d'authentification.
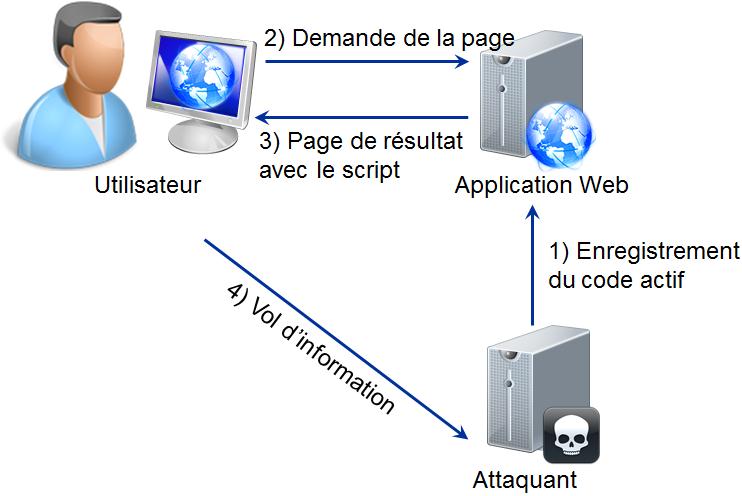
III-D-2. Exemples d'attaque▲
Parmi les attaques contre les systèmes d'authentification, la plus rÊpandue est l'utilisation de la force brute. Pour cela l'attaquant va bombarder la page d'authentification avec des valeurs d'identifiant et de mots de passe jusqu'à ce qu'il se fasse accepter [7]. L'attaque est facilitÊe si le message d'erreur de l'Êchec de l'authentification donne l'origine de l'erreur. Ainsi  l'utilisateur n'existe pas  permet à l'attaquant de ne pas tenter d'entrer des mots de passe pour cet utilisateur absent de la base de compte.  Mot de passe incorrect  permet à l'attaquant de se concentrer sur cet utilisateur, ce qui lui fait gagner beaucoup de temps. De même si l'application Web offre un service pour crÊer un compte par lui-même et qu'au moment de la saisie de l'identifiant ce système indique si le compte existe dÊjà ou non, l'attaquant dispose d'un moyen pour trouver des comptes attaquables. L'impact de ce type d'attaque n'est pas seulement limitÊ à une usurpation d'identitÊ pour l'application Web. Un internaute utilise souvent les mêmes valeurs d'identifiant et de mot de passe pour de nombreuses applications prÊsentes sur le Web. L'attaquant peut donc tenter d'utiliser ces valeurs sur diffÊrentes applications Web.
Il est possible pour l'attaquant de chercher des couples identifiant/mot de passe sans faire appel Ă la force brute. L'attaquant va simplement tenter d'utiliser des comptes gĂŠnĂŠralement prĂŠsents dans les applications Web, comme ceux d'administration. Ceci est surtout possible lorsque les applications sont basĂŠes sur des outils Open Source qui ont des comptes crĂŠĂŠs automatiquement avec des mots de passe par dĂŠfaut connus du domaine public. L'attaquant n'a plus qu'Ă consulter le code source pour trouver une liste restreinte d'identifiants/mots de passe valides.
Les pages Web qui permettent de rĂŠinitialiser les mots de passe sont une faille importante pour l'usurpation d'identitĂŠ. En effet, pour s'assurer de l'identitĂŠ du demandeur, la plupart d'entre elles demandent une information que seule la personne est censĂŠe connaitre. Or avec les rĂŠseaux sociaux, les internautes partagent leur vie privĂŠe. Ces informations personnelles visibles de tous peuvent ĂŞtre les mĂŞmes que celles demandĂŠes dans les pages de rĂŠinitialisation de mot de passe. Dans ce cas l'attaquant peut dĂŠfinir un nouveau mot de passe qu'il pourra utiliser pour se connecter Ă l'application.
Pour voler un identifiant de session, l'attaque par la force brute est Êgalement possible. Dans ce cas l'attaquant va gÊnÊrer des valeurs et tenter de les utiliser comme identifiant de session. S'il rÊussit à trouver une valeur valide, il pourra utiliser l'application Web sans s'être authentifiÊ. Par ailleurs, une attaque XSS peut permettre de rÊcupÊrer un identifiant de session prÊsent dans le cookie de l'internaute. L'identifiant de session peut Êgalement être dÊcouvert par un attaquant en Êcoutant la transmission de donnÊes sur le rÊseau, en consultant les fichiers de journalisation sur le serveur par injection de commandes systèmes par exemple.
Une autre technique consiste à fournir un identifiant de session à la victime, par hameçonnage par exemple. L'utilisateur se connecte à l'application Web et s'authentifie. La session est crÊÊe en utilisant l'identifiant fourni. L'attaquant peut alors accÊder au site en fournissant l'identifiant fixÊ. L'identifiant peut être gÊnÊrÊ ou obtenu en Êmettant une requête vers l'application cible de l'attaque si l'application retourne un identifiant de session pour toute requête avant même l'authentification de l'utilisateur.
Si l'identifiant de session n'est pas gĂŠnĂŠrĂŠ alĂŠatoirement, mais est un nombre incrĂŠmentĂŠ Ă chaque ouverture de session, par exemple, l'attaquant peut arriver Ă deviner un identifiant valide.
III-D-3. Parade et bonnes pratiques▲
Concernant les systèmes d'authentification, l'application ne doit accepter que des mots de passe suffisamment forts pour Êviter d'être devinÊs rapidement par la force brute. Une longueur minimale de huit caractères est ce qui recommandÊ par l'OWASP pour les applications critiques. De plus il doit comporter au moins un chiffre, une lettre en minuscule et une lettre en majuscule.
Le message affichÊ lors d'un problème de validitÊ de l'identifiant ou du mot de passe doit être gÊnÊrique et ne doit pas donner d'indice quant à l'origine de l'erreur.
Pour contrer les attaques de force brute, le compte ciblÊ par l'attaque doit être verrouillÊ après cinq tentatives consÊcutives infructueuses de connexion. La procÊdure de dÊverrouillage peut être automatique après un laps de temps prÊdÊfini ou manuelle par un administrateur de l'application.
Dans la mesure du possible il est conseillÊ de ne pas dÊvelopper son propre mÊcanisme d'authentification. Il est prÊfÊrable d'utiliser un système existant ÊprouvÊ.
Concernant les identifiants de session, les applications Web doivent limiter la durĂŠe de vie d'une session. Une pĂŠriode d'inactivitĂŠ maximale doit ĂŞtre dĂŠfinie. Si l'utilisateur n'utilise pas l'application pendant ce laps de temps, la session devient inutilisable et l'utilisateur doit se reconnecter. Une session doit ĂŠgalement avoir une durĂŠe de vie maximale au-delĂ de laquelle la session expire, mĂŞme si la pĂŠriode d'inactivitĂŠ autorisĂŠe n'ĂŠtait pas dĂŠpassĂŠe. Ces prĂŠcautions permettent de limiter le temps d'action d'un attaquant.
Du cĂ´tĂŠ client, du code JavaScript doit fermer la session lorsque l'utilisateur ferme le navigateur. Cela permet de simuler une action de l'utilisateur pour se dĂŠconnecter de l'application. Pour que l'utilisateur ĂŠvite de perdre des saisies non sauvegardĂŠes, du code JavaScript peut prĂŠvenir l'utilisateur que sa session va bientĂ´t expirer.
L'identifiant de session doit ĂŞtre gĂŠnĂŠrĂŠ automatiquement et ĂŞtre suffisamment long pour se prĂŠmunir des vols par prĂŠdiction.
Pour dÊtecter des attaques de force brute, il faut rÊgulièrement consulter les journaux d'activitÊ à la recherche d'ÊvÊnements inhabituels, comme un nombre important de requêtes utilisant des identifiants de sessions invalides.
III-E. RĂŠfĂŠrence directe non sĂŠcurisĂŠe Ă un objet▲
III-E-1. Principe▲
Cette vulnÊrabilitÊ existe simplement parce que les paramètres de requêtes ne sont pas vÊrifiÊs avant traitement. Si le paramètre vulnÊrable fait rÊfÊrence à un fichier ou à une valeur dans une base de donnÊes, il suffit de reconstruire la requête avec une valeur de paramètre normalement interdite pour y avoir accès.
Cette faille peut avoir des impacts importants si un utilisateur mal intentionnÊ obtient par ce biais des accès à des informations et des fonctionnalitÊs pour lesquelles il n'a aucune autorisation.
III-E-2. Exemples d'attaque▲
Cette faille est une des bases de la vulnÊrabilitÊ exploitÊe par XSS. En effet, dans les exemples d'attaques exposÊs prÊcÊdemment (voir paragraphe 3.3.2), les paramètres rÊcupÊrÊs ne sont pas vÊrifiÊs. Par contre, si ces valeurs avaient ÊtÊ contrôlÊes, les caractères spÊciaux n'auraient pas ÊtÊ autorisÊs, empêchant ainsi l'envoi de code frauduleux au navigateur.
Si les paramètres sont passÊs en paramètre d'un lien, un utilisateur malintentionnÊ peut aisÊment modifier l'adresse pour accÊder à des informations auxquelles il n'aurait pas dÝ avoir accès. L'exemple suivant reprend la table  comptes  (voir paragraphe 3.2.2) qui va être interrogÊe par un script PHP pour afficher le numÊro de carte bancaire de l'utilisateur.
<?php
//recuperation des parametres
$nom = $_GET['proprietaire'];
//generation de la requete
$requeteSQL = "SELECT numerocarte FROM comptes WHERE nom = '$nom'"; //execution de la requete
$reponse = mysql_query($requeteSQL);
$resultat = mysql_fetch_assoc($reponse);
//affichage du resultat
echo "<tr><td> Votre numero de carte est :</td><td>";
echo $resultat['numerocarte'];
echo "</td></tr>";
?>Si l'utilisateur malveillant saisit dans son navigateur l'adresse de cette page avec pour paramètre  nom=nom_de_la_victime , il a alors accès au numÊro de carte bancaire qu'il n'aurait jamais dÝ pouvoir voir.
III-E-3. Parade et bonnes pratiques▲
Pour protÊger les donnÊes les plus confidentielles ou les fonctionnalitÊs les plus avancÊes, le WASC recommande de demander à l'utilisateur de saisir à nouveau son identifiant et son mot avant de pouvoir y accÊder. Ensuite il suffit de se baser sur ces valeurs pour construire les requêtes. Ainsi dans l'exemple de l'affichage du numÊro de carte, le paramètre utilisÊ pour la recherche aurait ÊtÊ celui de la personne qui s'est authentifiÊe et non celui fourni en paramètre du lien.
III-F. Falsification de requĂŞtes intersites (CSRF)▲
III-F-1. Principe▲
D. Gollmann [12] montre qu'une attaque par falsification de requĂŞtes intersites (Cross-Site Request Forgery ou session riding ou CSRF ou XSRF) a un fonctionnement assez proche d'une attaque XSS. La principale diffĂŠrence est que l'utilisateur au travers de son navigateur ne sera pas la victime, mais sera celui qui va effectuer une action malveillante sur l'application cible. Une attaque CSRF va exĂŠcuter du code malveillant dans une application Web au travers de la session d'un utilisateur connectĂŠ.
Comme pour XSS, il existe deux modes opĂŠratoires.
Dans une attaque CSRF par rÊflexion (reflected CSRF), l'attaquant crÊe une page Web qui comporte un formulaire invisible par exemple. Ce dernier contient un script cachÊ qui lance des actions de l'application. L'attaquant piège l'utilisateur en mettant un lien vers cette page dans un courrier Êlectronique ou sur des rÊseaux sociaux. Quand l'utilisateur affiche cette page, le navigateur va interprÊter le code malicieux et va tenter d'exÊcuter une fonctionnalitÊ de l'application cible. Si l'utilisateur s'y est rÊcemment connectÊ, l'application va exÊcuter la commande sans le consentement de l'utilisateur. Cette attaque fonctionne, car les informations d'authentification qui ont prÊalablement ÊtÊ saisies par l'utilisateur sont envoyÊes automatiquement par le navigateur au serveur. L'attaquant n'a donc pas besoin de se connecter à l'application pour exÊcuter des commandes frauduleuses. Cependant l'attaque ne fonctionne pas si l'utilisateur ne s'est pas connectÊ.
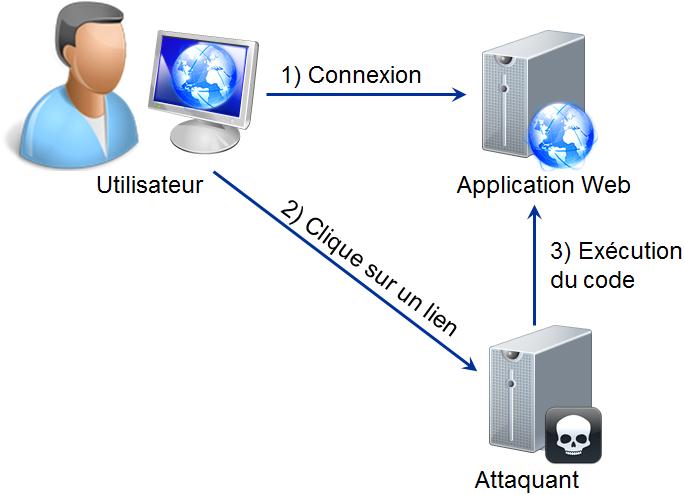
Dans une attaque CSRF stockĂŠe (stored CSRF), c'est l'application elle-mĂŞme qui prĂŠsente le code malicieux Ă l'utilisateur. Pour ce faire l'attaquant a rĂŠussi a insĂŠrĂŠ du code malicieux dans les donnĂŠes de l'application Web. Chaque fois qu'un utilisateur parcourra la page qui va prĂŠsenter ce code, le navigateur va l'interprĂŠter et par consĂŠquent va exĂŠcuter une commande de l'application. L'application va alors accepter d'exĂŠcuter cet ordre comme si la demande provenait de l'utilisateur. Cette attaque a plus de chances de rĂŠussir, car l'utilisateur s'est dĂŠjĂ connectĂŠ et utilise l'application. L'attaquant n'a pas de besoin de piĂŠger un utilisateur.
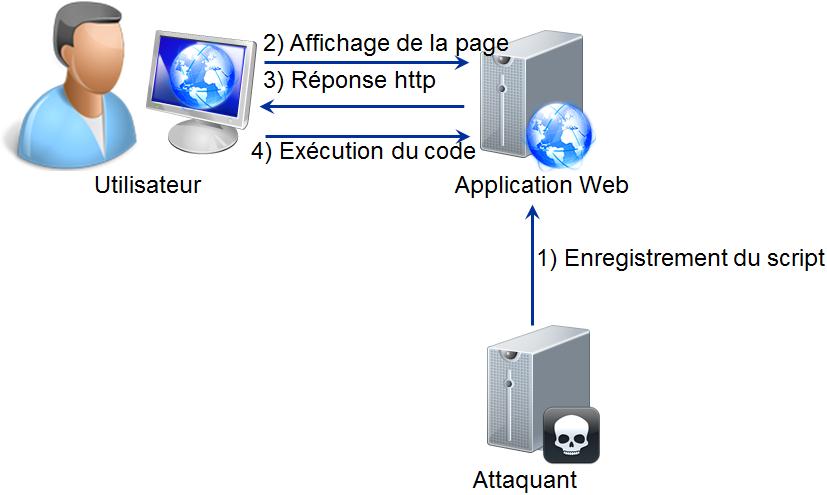
Une attaque par CSRF rend les dĂŠfenses contre les attaques XSS inopĂŠrantes.
III-F-2. Exemples d'attaque▲
L'exemple suivant reprend la table  messages  et le script PHP pour l'insertion de donnÊes (voir paragraphe 3.3.2). Si ce script se nomme  add_message.php , le site de l'attaquant pourra utiliser le code suivant pour le faire exÊcuter par l'utilisateur :
<form method="GET" id="reflected_CSRF" name="reflected_CSRF" action="add_message.php">
<input type=hidden name="numsujet" value="6">
<input type=hidden name="nom" value="CSRF">
<input type=hidden name="message" value="action frauduleuse">
</form>
<script>document.reflected_CSRF.submit()</script>L'utilisateur en parcourant la page de l'attaquant est alors automatiquement redirigÊ vers la page  add_message.php  avec les paramètres numsujet=6, nom=CSRF et message=action frauduleuse.
III-F-3. Parade et bonnes pratiques▲
Bien que XSS et CSRF soient proches dans le principe, se protĂŠger des attaques XSS ne permet pas de se protĂŠger des attaques CSRF.
Pour se protÊger, il faut utiliser uniquement des requêtes POST. Les mÊthodes GET doivent être bannies. Attention toutefois, dans les servlet Java la mÊthode  doGet()  fait appel à la mÊthode  doPost()  en redirigeant l'ensemble des paramètres. Dans ce cas l'utilisation de requêtes GET fonctionne. C'est pourquoi l'utilisation de POST n'est pas une protection suffisante.
Pour les pages qui manipulent des donnĂŠes sensibles, il faut demander Ă l'utilisateur de s'authentifier Ă nouveau. Cela permet de s'assurer que l'utilisateur est conscient de l'action et l'approuve.
L'utilisateur doit toujours vĂŠrifier que le lien sur lequel il clique est bien celui de l'application qu'il veut utiliser.
III-G. Mauvaise configuration de sĂŠcuritĂŠ▲
III-G-1. Principe▲
Cette faille de sÊcuritÊ regroupe toutes les vulnÊrabilitÊs laissÊes ouvertes aux diffÊrents niveaux de l'architecture de l'application Web. Pour chacun des serveurs impliquÊs dans l'activitÊ de l'application, le problème concerne le système d'exploitation ainsi que les outils installÊs pour servir l'application.
Pour chacun de ces composants, des failles sont connues du domaine public, ce qui facilite les attaques. S'ils ne sont pas mis Ă jour, l'attaquant peut exploiter les failles non corrigĂŠes.
Pour de nombreux outils, des options sont installĂŠes par dĂŠfaut alors qu'elles ne sont pas nĂŠcessaires au bon fonctionnement de l'application. Cette situation offre plus d'opportunitĂŠs pour un attaquant.
De mĂŞme de nombreuses applications sont installĂŠes avec des comptes crĂŠĂŠs avec des mots de passe par dĂŠfaut. Ces comptes et mots de passe sont les cibles privilĂŠgiĂŠes des usurpations d'identitĂŠ.
III-G-2. Exemples d'attaque▲
J. Scambray, V. Liu et C. Sima [7] donnent un exemple d'attaque. En 2007 une faille est dÊcouverte dans l'extension mod_jk du serveur HTTP Apache. Ce module permet de renvoyer les requêtes HTTP reçues par le serveur HTTP au serveur de Servlet Apache Tomcat pour qu'il exÊcute les Servlets Java. Le problème dÊtectÊ est un dÊpassement de mÊmoire tampon (buffer overflow). Le module ne gÊrait pas correctement les adresses trop longues contenues dans les requêtes HTTP. Cela permettait à un attaquant de faire ouvrir un port d'Êcoute spÊcifique utilisable pour prendre la main sur le serveur. Tant que le correctif n'Êtait pas publiÊ et installÊ, les systèmes restaient vulnÊrables. Le seul moyen de se protÊger Êtait de dÊsactiver le module s'il n'Êtait pas utilisÊ.
Les codes sources des applications Web Open Source sont disponibles aussi bien pour les dÊveloppeurs lÊgitimes que pour les attaquants. En parcourant ces fichiers, il est possible de lire des commentaires laissÊs par les dÊveloppeurs indiquant qu'il y a un problème dont ils ont conscience, mais qu'ils traiteront plus tard. Dans ce cas l'attaquant n'a plus qu'à exploiter cette faiblesse.
Les pages d'erreurs des serveurs HTTP contiennent par dÊfaut des informations sur l'erreur et sur le serveur HTTP lui-même. En tentant d'accÊder à une page inexistante, une erreur de type  404 page not found  est retournÊe à l'attaquant, de même que la version du serveur HTTP. Dans ce cas il suffit à l'attaquant d'Êtudier cette version pour en connaitre les vulnÊrabilitÊs et de les exploiter.
III-G-3. Parade et bonnes pratiques▲
L'ANSSI et l'OWASP font les recommandations suivantes.
Il faut dÊsactiver les options inutiles des composants afin de diminuer le nombre de vulnÊrabilitÊs potentielles que ce soit au niveau du système d'exploitation, du système de gestion de bases de donnÊes ou du serveur HTTP.
Il faut mettre à jour les diffÊrents composants de l'architecture autant que possible en installant les correctifs dès qu'ils sont publiÊs. De plus, à l'installation il est prÊfÊrable de choisir la version anglaise plutôt qu'une autre langue. En effet, lors du dÊveloppement de correctifs c'est toujours la version anglaise qui est privilÊgiÊe, les autres versions Êtant corrigÊes plus tardivement.
Après l'installation il faut dÊsactiver voire supprimer tous les comptes inutiles. Le mot de passe des autres comptes doit être modifiÊ dès que possible. Les comptes d'administration par dÊfaut doivent être verrouillÊs. Il faut prÊfÊrer l'utilisation de comptes d'administration crÊÊs manuellement.
III-H. Stockage de donnĂŠes cryptographiques non sĂŠcurisĂŠ▲
III-H-1. Principe▲
Cette faille de sÊcuritÊ englobe toutes les faiblesses liÊes à la protection du stockage des donnÊes. La meilleure protection est la mise en place du chiffrement des informations. Le CLUSIF dÊfinit le chiffrement comme  le procÊdÊ grâce auquel on peut rendre la comprÊhension d'un document impossible à toute personne qui n'en possède pas la clÊ. 
La principale faille concerne les donnĂŠes sensibles, c'est-Ă -dire les donnĂŠes dont la divulgation, l'altĂŠration ou la non-disponibilitĂŠ peuvent porter prĂŠjudice Ă leur propriĂŠtaire, telles que le mot de passe ou l'identifiant de session. Si les donnĂŠes sont prĂŠsentes en clair ou chiffrĂŠes par un algorithme faible, il existe un risque qu'un attaquant puisse les consulter.
III-H-2. Exemples d'attaque▲
Certains moteurs de bases de donnÊes font payer l'option de chiffrement. Pour des raisons d'Êconomies, les responsables dÊcident de stocker les donnÊes en clair dans la base de donnÊes. Seules les transmissions de requête HTTP sur le rÊseau sont chiffrÊes. Pour se protÊger du risque d'incendie sur le site oÚ sont installÊs les serveurs, les donnÊes sauvegardÊes sur bande sont envoyÊes sur un autre site une fois par mois. Si un agresseur intercepte cette sauvegarde pendant son transfert, il aura accès aux donnÊes en clair.
III-H-3. Parade et bonnes pratiques▲
Tous les moyens de stockage de donnĂŠes sensibles doivent ĂŞtre chiffrĂŠs. Il faut s'assurer ĂŠgalement que la sauvegarde du moyen de stockage ne contient pas les donnĂŠes en clair.
Il ne faut pas utiliser d'algorithme de chiffrement ou de hachage faible, tel que MD5 ou SHA1 ni tenter de crĂŠer son propre algorithme. Il faut utiliser des algorithmes reconnus et ĂŠprouvĂŠs tels AES-256, RSA et SHA-256. Pour des raisons de capacitĂŠ de calcul, l'ANSSI recommande que la taille minimale des clĂŠs symĂŠtriques utilisĂŠes jusqu'en 2020 soit de 100 bits et de 128 bits au-delĂ de 2020.
III-I. DĂŠfaillance dans la restriction des accès Ă une URL▲
III-I-1. Principe▲
Cette faille permet Ă un utilisateur d'accĂŠder Ă des fonctionnalitĂŠs de l'application, voire des fichiers et rĂŠpertoires du serveur HTTP sans y ĂŞtre habilitĂŠ.
L'attaque par traversÊe de rÊpertoires permet d'accÊder à des fichiers du serveur HTTP notamment ceux contenant les clÊs privÊes de chiffrement. Les applications vulnÊrables ouvrent des fichiers dont le nom est donnÊ en paramètre de la requête HTTP.
Une autre attaque consiste à deviner l'existence de fichiers ou de rÊpertoires. En effet de nombreux outils disposent d'une interface d'administration, dont l'adresse d'accès est du type  http://www.site_vulnerable.fr/admin/admin.php . Dans ce cas même si l'utilisateur malintentionnÊ n'y a pas accès au travers de l'application, il peut saisir directement l'adresse pour l'ouvrir. Les applications vulnÊrables ne demandent pas de s'authentifier avant de pouvoir l'utiliser, la seule protection Êtant qu'aucun lien n'est mis à disposition pour y accÊder, ce qui n'est pas suffisant.
Une attaque ĂŠquivalente consiste Ă ne pas spĂŠcifier de nom de fichier dans l'adresse, par exemple ÂŤÂ http://www.site_vulnerable.fr/admin/Â Âť. Les serveurs HTTP vulnĂŠrables afficheront le contenu du rĂŠpertoire.
III-I-2. Exemples d'attaque▲
L'exemple suivant montre une portion de code vulnĂŠrable Ă l'attaque par traversĂŠe de chemin. L'application est construite pour inclure du texte en fonction de la langue du navigateur. Dans ce cas la langue est donnĂŠe en paramètre de la requĂŞte HTTP, la commande PHP ÂŤÂ include lang_nom_fichier.php  permet dâinclure le contenu du fichier concernĂŠ.
<?php
$language="entete-en";
if (isset($_GET['lang'])) {
$language=$_GET['lang'];
}
include ("/usr/local/webapp/template/" . $language . ".php")
?>Si l'attaquant envoie la requête avec le paramètre  lang=../../../../etc/passwd , il aura accès au fichier des mots de passe du système et tentera de se connecter au serveur HTTP avec un des comptes ainsi trouvÊs.
Dans cet exemple l'attaque par traversĂŠe de chemin est possible Ă cause de la faille RĂŠfĂŠrence directe non sĂŠcurisĂŠe Ă un objet (voir paragraphe III.E).
III-I-3. Parade et bonnes pratiques▲
Pour se protÊger des dÊfaillances dans la restriction des accès à une URL, il ne faut pas autoriser les caractères douteux tels que  /  et  \ .
Pour se prĂŠmunir des attaques par traversĂŠe de chemin, il faut ĂŠtablir une liste de fichiers utilisables et refuser tout autre fichier. La correction Ă apporter Ă l'exemple ci-dessus est la suivante.
<?php
$languages=array("entete-en","entete-fr","entete-es");
$language=$languages[1];
if (isset($_GET['lang'])) {
$tmp=$_GET['lang'];
if (array_search($tmp, $languages)) {
$language=$tmp;
}
}
include ("/usr/local/webapp/template/" . $language . ".php")
?>Tous les rĂŠpertoires doivent contenir un fichier index.html, ce qui ĂŠvite de pouvoir accĂŠder au rĂŠpertoire lui-mĂŞme. De plus, les serveurs HTTP doivent ĂŞtre configurĂŠs pour ne pas permettre l'affichage du contenu des rĂŠpertoires.
Pour Êviter les accès à des fonctionnalitÊs sans autorisation, ces dernières doivent être protÊgÊes en vÊrifiant que l'utilisateur a le droit de les utiliser. Ne pas afficher de lien pour y accÊder n'est pas une protection suffisante.
III-J. Protection insuffisante de la couche transport▲
III-J-1. Principe▲
Comme ĂŠvoquĂŠ pour le stockage des donnĂŠes sensibles, celles-ci ne doivent apparaĂŽtre en clair qu'aux personnes autorisĂŠes. Sur Internet il existe un risque qu'une requĂŞte ou une rĂŠponse HTTP soit interceptĂŠe. Si elle contient des informations confidentielles transmises en clair, alors l'attaquant pourra les exploiter facilement.
Tous les rĂŠseaux de l'architecture de l'application Web sont concernĂŠs, depuis le navigateur de l'utilisateur jusqu'au stockage des donnĂŠes, en passant par le serveur Web.
III-J-2. Exemples d'attaque▲
L'attaque du type  Homme du milieu  (ou  Man-in-the-Middle ) est une des attaques les plus rÊpandues pour accÊder aux donnÊes d'une application [7]. Si un attaquant rÊussit à compromettre un serveur proxy, il pourra intercepter toutes les communications. Si en plus ce serveur est responsable du chiffrement des flux HTTP, il aura accès aux donnÊes les plus sensibles qui devaient être chiffrÊes.
Si une partie de l'application seulement est protÊgÊe par chiffrement, alors l'application complète est vulnÊrable. Souvent, seule la page de connexion contenant le formulaire de saisie de l'identifiant et du mot de passe est chiffrÊe. Si l'utilisateur après s'être authentifiÊ retourne sur des pages non chiffrÊes, alors des informations, telles que le nom de l'utilisateur ou l'identifiant de session, peuvent être transmises en clair de page en page, exposant ainsi toute l'application à des attaques d'usurpation d'identitÊ (voir paragraphe III.D).
III-J-3. Parade et bonnes pratiques▲
Si une application Web manipule des donnĂŠes sensibles, il faut mettre en place du chiffrement SSL pour TOUTES les pages. De plus, les mots de passe et les identifiants de session ne doivent Ă aucun moment transiter en clair. Pour cela, il est possible de configurer le serveur Web pour rediriger automatiquement toutes les requĂŞtes HTTP vers les pages chiffrĂŠes.
La protection de la couche  transport  vient en complÊment de la protection du stockage des donnÊes. Ainsi si les donnÊes stockÊes sont chiffrÊes, il faut s'assurer que tous les moyens de communication le soient aussi. Par exemple, la politique de sÊcuritÊ pour les donnÊes mÊdicales exige que le mÊdecin du travail et le patient soient les seuls autorisÊs à consulter ces informations. Pour cela, au niveau de l'application, il faut s'assurer que l'utilisateur est soit la personne concernÊe, soit le praticien. De plus, les informations ne doivent apparaÎtre en clair à aucun autre moment que pour l'affichage. Cela concerne les flux de communication entre l'utilisateur et les diffÊrents composants de l'architecture tels que le serveur HTTP ou la base de donnÊes, mais aussi les moyens de stockage tels que les fichiers, les bases de donnÊes ou les sauvegardes de ces derniers.
III-K. Redirection et renvois non validĂŠs▲
III-K-1. Principe▲
Les redirections d'adresse sont utilisÊes dans les applications Web pour effectuer un changement de page en fonction d'un paramètre.
L'utilisation de la redirection est particulièrement utilisÊe pour les attaques par hameçonnage (ou phishing). En cliquant sur un lien utilisant une page de redirection, l'utilisateur est automatiquement emmenÊ vers une autre page. Cette redirection peut être utilisÊe dans le cadre d'une attaque CSRF (voir paragraphe III.F).
III-K-2. Exemples d'attaque▲
Le script suivant est un exemple de page de redirection en utilisant la redirection par code HTML.
<?php
$nouvelleAdresse='http://nouvelle.adresse.fr/index.php';
if (isset($_GET['adresse'])) {
$nouvelleAdresse=$_GET['adresse'];
}
echo '<!DOCTYPE html>'."\n",
'<html xmlns="http://www.w3.org/1999/xhtml">'."\n",
'<head>'."\n",
'<meta charset="UTF-8" />'."\n",
//Redirection HTML : '<meta http-equiv="refresh" content="0; url='.$nouvelleAdresse.'" />'."\n",
'<title>Redirection</title>'."\n",
'<meta name="robots" content="noindex,follow" />'."\n",
'</head>'."\n",
"\n",
'<body>'."\n",
//au cas oĂš la redirection ne fonctionne pas :
'<p><a href="'.$nouvelleAdresse.'">Redirection</a></p>'."\n",
'</body>'."\n",
'</html>'."\n";
?>Si un attaquant a connaissance d'une page de redirection vulnĂŠrable, il peut l'utiliser dans un lien pour faire rediriger l'utilisateur vers une page Web.
<a href="http://www.application-securisee.com/redirect.php?www.attaquant.com/attaque.php">
http://www.application-securisee.com</a>Dans ce cas l'utilisateur est leurrĂŠ. Le lien pointe bien vers l'application, mais va le rediriger vers une page malveillante.
III-K-3. Parade et bonnes pratiques▲
La redirection ne doit renvoyer qu'à des pages locales. Dans ce cas les caractères spÊciaux doivent être prohibÊs.
En cas de changement d'adresse ou de dÊplacement d'une page, il vaut mieux utiliser la redirection paramÊtrÊe dans le serveur HTTP. Par exemple avec Apache il est possible de placer un fichier  .htaccess  pour paramÊtrer les redirections automatiques.
<IfModule mod_alias.c>
#redirection automatique d'une page vers une nouvelle adresse
Redirect permanent /dossier01/script_1.html http://nouvelle.adresse.fr/dossier03/script_1.php
#redirection automatique d'un ensemble de pages
RedirectMatch permanent /dossier01/(.*)\.html$ http://nouvelle.adresse.fr/dossier02/$1.php
#redirection automatique d'un dossier vers une nouvelle adresse
Redirect permanent /dossier01 http://nouvelle.adresse.fr/dossier02
#redirection automatique de toute l'application Web vers une nouvelle adresse
Redirect permanent / http://nouvelle.adresse.fr/
</IfModule>IV. Bonnes Pratiques▲
IV-A. Règles de dĂŠveloppement▲
Il est possible de se protÊger de la plupart des attaques expliquÊes prÊcÊdemment en suivant quelques règles de dÊveloppement.
IV-A-1. Toutes les donnĂŠes doivent ĂŞtre vĂŠrifiĂŠes▲
Les valeurs saisies dans un formulaire doivent être validÊes au niveau du navigateur avec du code JavaScript, car le client n'est pas une source fiable. Les valeurs doivent Êgalement être contrôlÊes au niveau du serveur au moment de la rÊcupÊration des paramètres, tout comme les paramètres de requête. Il n'est pas certain que ce soit l'utilisateur de l'application qui envoie la requête HTTP. Ainsi pour chaque valeur :
- vÊrifier que le type correspond à celui attendu ;
- pour plus de sÊcuritÊ, caster les donnÊes avant de les mettre dans des variables ;
- coder les caractères spÊciaux avec le code HTML correspondant ;
- vÊrifier la prÊsence de tous les arguments attendus ;
- pour les nombres, contraindre la valeur entre deux bornes ;
- pour les listes, vĂŠrifier que la valeur appartient Ă la liste des valeurs autorisĂŠes (select, radio, checkboxâŚ) ;
- contraindre la longueur de la valeur saisie avec une taille minimale et une taille maximale ;
- vÊrifier la valeur avec une expression rÊgulière ;
- n'accepter que les lettres de l'alphabet et/ou les chiffres par dÊfaut, tous les autres caractères devant être refusÊs. Dans le cas oÚ d'autres caractères doivent être autorisÊs, ils doivent être limitÊs à une liste prÊdÊfinie ou être remplacÊs par les codes HTML ;
- vÊrifier si la valeur nulle doit être acceptÊe ;
- dÊfinir le jeu de caractères de la donnÊe.
Même les donnÊes envoyÊes vers l'utilisateur doivent être vÊrifiÊes, avec au minimum les actions suivantes :
- coder les caractères spÊciaux avec le code HTML correspondant ;
- dÊfinir le jeu de caractères de la page.
IV-A-2. PrivilĂŠgier l'utilisation des requĂŞtes POST▲
Cela permet de ne pas prendre en compte des paramètres frauduleux dans les adresses.
IV-A-3. Utiliser les requĂŞtes paramĂŠtrĂŠes▲
Les requĂŞtes SQL ne doivent pas ĂŞtre construites dynamiquement. Ainsi, les requĂŞtes SQL ne peuvent pas ĂŞtre parasitĂŠes comme c'est le cas dans le cas de l'injection SQL (voir paragraphe III.B).
IV-A-4. Ne pas rĂŠinventer la roue▲
Dans la mesure du possible, il est prÊfÊrable d'utiliser des outils existants plutôt que de dÊvelopper des fonctionnalitÊs souvent prÊsentes dans les applications, comme les systèmes d'authentification ou de rÊinitialisation de mot de passe.
IV-A-5. SĂŠcuriser l'accès aux donnĂŠes▲
Toutes les pages d'une application Web doivent s'assurer que l'utilisateur s'est authentifiĂŠ prĂŠalablement. Pour les fonctionnalitĂŠs manipulant des donnĂŠes sensibles, l'application doit demander Ă l'utilisateur de s'authentifier Ă nouveau avant de les afficher.
Cela permet de s'assurer qu'il n'y a pas eu usurpation d'identitĂŠ. Les messages d'erreur renvoyĂŠs doivent ĂŞtre gĂŠnĂŠriques pour ne pas aiguiller les attaquants potentiels.
Les donnĂŠes sensibles doivent ĂŞtre chiffrĂŠes dans les bases de donnĂŠes.
La protection des mots de passe, des identifiants de session et des cookies permet de se prÊmunir contre l'usurpation d'identitÊ. Pour cela, le mot de passe doit avoir au moins huit caractères, voire dix pour les accès aux donnÊes sensibles. Il doit Êgalement contenir au moins trois types de caractères, tels que des chiffres, des lettres minuscules, des lettres majuscules ou des caractères spÊciaux. Il doit avoir une pÊriode de validitÊ de maximum quatre-vingt-dix jours. Au-delà , il doit être changÊ. Le compte de l'utilisateur doit être verrouillÊ, au moins temporairement, si cinq tentatives de connexion consÊcutives ont ÊchouÊ. Le mot de passe doit être chiffrÊ ou hachÊ avec un algorithme fort. Seule sa valeur chiffrÊe sera comparÊe lors de l'authentification de l'utilisateur.
Les identifiants de session doivent avoir une durÊe de vie limitÊe au-delà de laquelle il n'est plus utilisable. De même, après une pÊriode d'inactivitÊ prÊdÊfinie, l'identifiant de session doit être invalidÊ. En cas de fermeture du navigateur, l'identifiant de session doit être supprimÊ. Ces actions sont Êquivalentes à un système de dÊconnexion automatique.
Les cookies doivent être protÊgÊs en positionnant deux attributs :  Secure  permet d'interdire l'envoi du cookie sur un canal non chiffrÊ,   HTTPonly  permet d'en interdire l'accès à JavaScript.
IV-B. Configuration des composants serveur▲
Pour des raisons de capacitĂŠ de calcul, la taille minimale des clĂŠs symĂŠtriques utilisĂŠes jusqu'en 2020 doit ĂŞtre de 100 bits et de 128 bits au-delĂ de 2020.
Si le caractère confidentiel des donnÊes nÊcessite la mise en place du chiffrement des flux, toutes les pages doivent être protÊgÊes et pas seulement celles manipulant ces donnÊes.
Les outils installĂŠs doivent ĂŞtre mis Ă jour avec le correctif le plus rĂŠcent.
Les options inutilisÊes des outils installÊs doivent être supprimÊes ou dÊsactivÊes. Les comptes crÊÊs lors de l'installation des outils doivent être au minimum verrouillÊs ; le plus sÝr Êtant de les supprimer.
Le serveur HTTP ne doit pas afficher le contenu d'un rĂŠpertoire.
IV-C. Audit▲
Pendant la phase de dÊveloppement, les tests unitaires permettent de vÊrifier le comportement d'une fonction de l'application. Ils peuvent être utilisÊs pour s'assurer que les règles de dÊveloppement citÊes prÊcÊdemment sont respectÊes. En complÊment, les outils d'intÊgration continue, tels que  Jenkins  ou  Hudson , permettent de vÊrifier à chaque modification de code qu'elle n'engendre pas de rÊgression. L'utilisation conjointe de cette panoplie d'outils facilite les audits de code et permet même de les automatiser lors des phases de maintenance.
De plus, l'OWASP offre des outils de test du code et du comportement des applications Web. Ainsi, l'outil  Code Crawler  permet d'analyser le code d'applications .NET et Java.  WebScarab  agit comme un serveur proxy et permet à l'auditeur d'analyser les Êchanges HTTP pour chercher des failles de sÊcuritÊ.  Zed Attack Proxy  est un scanner qui permet de dÊtecter automatiquement certaines vulnÊrabilitÊs. Quant au WASC, il ne fournit pas d'outil, mais un guide pour comparer les diffÊrentes offres commerciales ou non d'automatisation de dÊtection des problèmes liÊs à la sÊcuritÊ des applications Web.
Par ailleurs, en condition opĂŠrationnelle, les fichiers de journalisation des diffĂŠrents composants de l'architecture doivent faire l'objet d'un audit rĂŠgulier afin de s'assurer que l'application ou le serveur n'a pas ĂŠtĂŠ victime de tentative d'attaque par la force brute.
V. Conclusion▲
V-A. Constat▲
Depuis la version de 2004, le classement de l'OWASP a peu ÊvoluÊ. En effet, sept problèmes rÊpertoriÊs en 2010 Êtaient dÊjà prÊsents en 2004 comme le montre le tableau ci-dessous.
|
Risques |
2004 |
2007 |
2010 |
|---|---|---|---|
|
Injection de commandes |
A6 |
A2 |
A1 |
|
Failles Cross Site Scripting (XSS) |
A4 |
A1 |
A2 |
|
Violation de Gestion d'Authentification et de Session |
A3 |
A7 |
A3 |
|
RĂŠfĂŠrence directe Ă un objet non sĂŠcurisĂŠe |
A1 |
A4 |
A4 |
|
Cross Site Request Forgery (CSRF) |
A5 |
A5 |
|
|
Gestion de configuration non sĂŠcurisĂŠe |
A10 |
A6 |
|
|
Stockage non sĂŠcurisĂŠ |
A8 |
A8 |
A7 |
|
Manque de restriction d'accès URL |
A2 |
A10 |
A8 |
|
Communications non sĂŠcurisĂŠes |
A9 |
A9 |
|
|
Redirection et renvoi non validĂŠs |
A10 |
||
|
DĂŠbordement de tampon |
A5 |
||
|
Mauvaise gestion des erreurs |
A7 |
A6 |
|
|
DĂŠni de Service |
A9 |
||
|
ExĂŠcution de fichier malicieux |
A3 |
Cela signifie que le Web 2.0 a apportÊ du confort à l'utilisateur, mais n'a pas apportÊ des failles plus dangereuses que celles dÊjà prÊsentes. En effet, AJAX permet d'Êtendre les possibilitÊs des attaques. Ainsi, le vol d'informations par CSRF prend une nouvelle forme. Tout comme l'attaque CSRF classique expliquÊe dans le paragraphe 3.6, un utilisateur ouvre une page Web frauduleuse. Ensuite l'attaquant profite du mode asynchrone de la fonction  XMLHttpRequest  pour parcourir la page de l'application affichÊe, voler le cookie et envoyer les donnÊes à l'attaquant. Les protections contre CSRF restent efficaces, mais se protÊger de la seconde phase de l'attaque est plus dÊlicat. Par ailleurs AJAX permet d'outrepasser la protection interdomaine offerte par les navigateurs.
Bien que de nouvelles failles Êmergent avec le Web 2.0, les applications Web sont toujours vulnÊrables aux failles les plus anciennes. Cela dÊmontre que le comportement des dÊveloppeurs n'a pas changÊ. PressÊs par des contraintes de temps, ils ne font pas l'effort d'appliquer quelques règles de base qui permettent de se dÊfendre contre les attaques les plus dangereuses.
V-B. Perspectives▲
2012 va marquer l'arrivÊe de nouveaux standards : HTML 5 et CSS 3. Leur objectif est de combler les lacunes de leurs prÊdÊcesseurs utilisÊs depuis bientôt quinze ans. Les dÊveloppeurs espèrent qu'avec ces nouvelles versions, l'utilisation de JavaScript diminue, allÊgeant ainsi le code des applications Web et diminuant par la même occasion le nombre des vulnÊrabilitÊs. Le coÝt de mise à jour des applications Web actuelles risque de freiner l'adoption de ces nouvelles normes. Les organismes de sÊcuritÊ devront Êgalement s'impliquer pour mettre à disposition des dÊveloppeurs de nouvelles bonnes pratiques.
VI. Bibliographie▲
[1] L. Shklar et R. Rosen. Web Application Architecture: Principles, Protocols and Practices. John Wiley & Sons Ltd, 372p, 2003
[2] S. Gulati. Under the hood of the Internet: Connector: the Internet protocol, part one: the foundations. Magazine Crossroads 6, article 3, 2000
[3] G.Florin et S.Natkin. Support de cours RESEAUX ET PROTOCOLES. CNAM, 884p, 2007
[4] J. Governor, D. Hinchcliffe et D. Nickull. Web 2.0 Architectures. O'Reilly Media, 248p, 2009
[5] C. Porteneuve et T. Nitot. Bien dĂŠvelopper pour le Web 2.0Â : Bonnes pratiques Ajax. Eyrolles, 673p, 2008
[6] M. Contensin. SĂŠcuritĂŠ des applications Web dans formation PHP/MySQL chapitre 6. CNRS, 2007
[7] J. Scambray, V. Liu et C. Sima. Hacking Exposed Web Applications: Web Application Security Secrets and Solutions. Osborne/McGraw-Hill, 482p, 2010
[8] H. Dwivedi, A. Stamos, Z. Lackey et R. Cannings. Hacking Exposed Web 2.0: Web 2.0 Security Secrets and Solutions. Osborne/McGraw-Hill, 258p, 2007
[9] Z. Su et G. Wassermann. The essence of command injection attacks in Web applications. Dans POPL'06 Conference, ACM SIGPLAN Notices, p372-384, 2006
[10] Y.-W. Huang, C.-H. Tsai, T.-P. Lin, S.-K. H., D.T. Lee et S.-Y. Kuo. A testing framework for Web application security assessment. Dans Computer Networks, pages 739-761, 2005
[11] A. Kiezun, P. J. Guo, K. Jayaraman, M. D. Ernst. Automatic Creation of SQL Injection and Cross-Site Scripting Attacks. Dans ICSE, pages 199-209, 2009
[12] D. Gollmann. Securing Web applications. Dans Information Security Technical Report, chapitre 1-9, Elsevier, 2008
Les sites Web citĂŠs ci-dessous sont considĂŠrĂŠs comme des sources fiables par les organismes ĂŠvoquĂŠs prĂŠcĂŠdemment.
- http://csrc.nist.gov/publications/ consultĂŠ le 27/11/2011.
- http://erratasec.blogspot.com/ consultĂŠ le 26/01/2012.
- http://ferruh.mavituna.com/sql-injection-cheatsheet-oku/ consultĂŠ le 27/11/2011.
- http://ha.ckers.org/ consultĂŠ le 27/11/2011.
- http://googlewebmastercentral.blogspot.com/2009/01/open-redirect-urls-is-your-site-being.html consultĂŠ le 27/11/2011.
- http://jeremiahgrossman.blogspot.com/2010/01/wasc-threat-classification-to-owasp-top.html consultĂŠ le 26/01/2012.
- http://references.modernisation.gouv.fr/ consultĂŠ le 21/11/2011.
- http://www.certa.ssi.gouv.fr/ consultĂŠ le 21/11/2011.
- http://www.cgisecurity.com/ consultĂŠ le 27/11/2011.
- http://www.checkmarx.com/ consultĂŠ le 27/11/2011.
- http://www.clusif.asso.fr/ consultĂŠ le 21/11/2011.
- http://www.cnil.fr/ consultĂŠ le 03/12/2011.
- http://www.dgdr.cnrs.fr/fsd/ consultĂŠ le 19/11/2011.
- http://www.dwheeler.com/secure-programs/ consultĂŠ le 27/11/2011.
- http://www.ietf.org/ consultĂŠ le 27/11/2011.
- http://www.legifrance.gouv.fr/ consultĂŠ le 10/12/2011.
- http://www.ouah.org/chambet.html consultĂŠ le 27/11/2011.
- https://www.owasp.org/ consultĂŠ le 19/11/2011.
- http://www.pcmag.com/article2/0,4149,11525,00.asp consultĂŠ le 10/12/2011.
- http://www.references.modernisation.gouv.fr/rgs-securite consultĂŠ le 27/11/2011.
- http://www.resinfo.org/ consultĂŠ le 20/11/2011.
- http://www.rsa.com/ consultĂŠ le 10/12/2011.
- http://www.schneier.com/blog/archives/2005/10/scandinavian_at_1.html consultĂŠ le 27/11/2011.
- http://www.ssi.gouv.fr/ consultĂŠ le 21/11/2011.
- http://www.w3.org/ consultĂŠ le 21/11/2011.
- http://www.webappsec.org/ consultĂŠ le 21/11/2011.
- http://yehg.net/lab/ consultĂŠ le 27/11/2011.
Source des icônes libres de droits d'utilisation : http://findicons.com
VII. Remerciements▲
Je tiens Ă remercier ClaudeLELOUP et Erielle pour la relecture orthographique attentive de cet article.
