


I. HTTP aujourd'hui▲
Le protocole HTTPÂ 1.1 est omniprÃĐsent sur Internet. De nombreux investissements ont ÃĐtÃĐ rÃĐalisÃĐs sur des protocoles et infrastructures tirant profit de celui-ci. Ã tel point que lors de l'implÃĐmentation d'un nouveau projet, il est souvent plus facile d'utiliser HTTP plutÃīt que de dÃĐvelopper un nouveau protocole.
I-A. HTTP 1.1 est ÃĐnorme▲
Lors de la crÃĐation de HTTP, il fut probablement perçu comme un protocole plutÃīt simple et ÃĐvident, ce qui, avec le temps, s'est rÃĐvÃĐlÃĐ faux. HTTP 1.0 spÃĐcifiÃĐ dans la RFC 1945 est une spÃĐcification de 60 pages datant de 1996. La RFC 2616 qui dÃĐcrit HTTP 1.1 a ÃĐtÃĐ publiÃĐe trois ans plus tard en 1999 et comprend 176 pages. Puis, quand nous, à l'IETF, avons mis à jour cette spÃĐcification, elle a ÃĐtÃĐ rÃĐpartie en six documents, avec davantage de pages au total (RFC 7230 et associÃĐes). HTTP 1.1 est ÃĐnorme, compte tenu des nombreux dÃĐtails, subtilitÃĐs et nombreux points optionnels.
I-B. Une flopÃĐe d'options▲
De par sa nature, HTTP 1.1 possÃĻde plusieurs options et petits dÃĐtails permettant l'ajout d'extensions ultÃĐrieures. Ce qui a menÃĐ Ã un ÃĐcosystÃĻme logiciel oÃđ aucune implÃĐmentation n'a tout couvert (encore faut-il dÃĐfinir ce que ÂŦ tout Âŧ reprÃĐsente). Cela a menÃĐ Ã un cercle vicieux oÃđ les fonctionnalitÃĐs peu utilisÃĐes ont ÃĐtÃĐ peu implÃĐmentÃĐes ce qui en limitait l'utilitÃĐ pour ceux qui en faisaient usage.
Plus tard, cela a causÃĐ des problÃĻmes d'interopÃĐrabilitÃĐ entre clients et serveurs qui utilisaient certaines de ces fonctionnalitÃĐs. Le pipelining HTTP en est un exemple parlant.
I-C. Usage incorrect de TCP▲
HTTP 1.1 a du mal à vraiment tirer parti de la puissance et des performances offertes par TCP. Les clients et navigateurs HTTP doivent Être trÃĻs crÃĐatifs pour trouver des solutions qui abaissent les temps de chargement de pages web.
D'autres expÃĐrimentations menÃĐes en parallÃĻle à travers les annÃĐes ont confirmÃĐ qu'il est difficile de remplacer TCP et qu'il fallait donc amÃĐliorer à la fois TCP et les protocoles au-dessus.
En clair, TCP peut Être utilisÃĐ Ã meilleur escient en ÃĐvitant les pauses ou en utilisant certains moments pour envoyer et recevoir des donnÃĐes. Les chapitres suivants dÃĐvelopperont ces points.
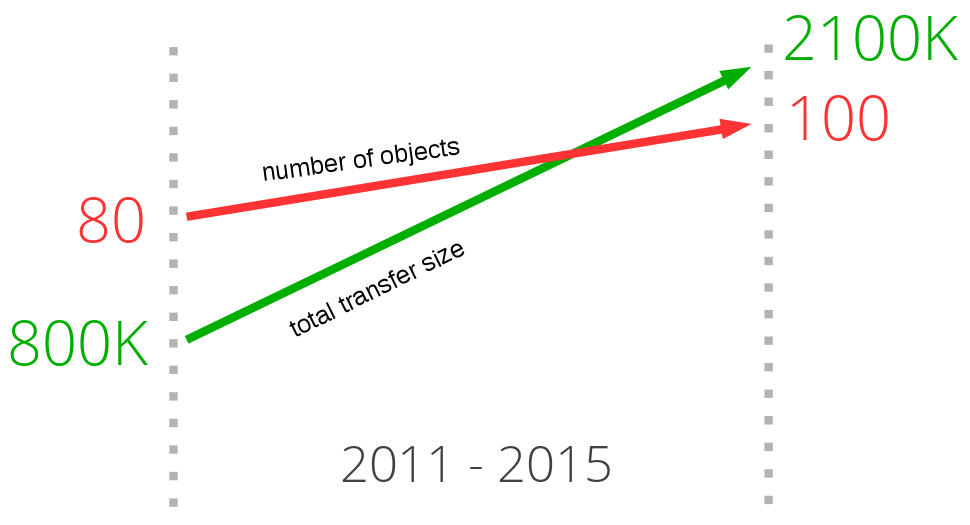
I-D. Volume de donnÃĐes et nombre d'objets▲
En regardant la tendance parmi les sites les plus importants sur le web aujourd'hui et ce que cela implique pour tÃĐlÃĐcharger leurs pages d'accueil, une tendance se dÃĐgage. Au fil des annÃĐes, le nombre de donnÃĐes à transfÃĐrer a augmentÃĐ rÃĐguliÃĻrement pour atteindre et mÊme surpasser 1,9 Mo. Plus important encore, le nombre moyen de ressources distinctes (ou objets) va au-delà de la centaine pour afficher chaque page.
Le graphique ci-dessous montre que cette tendance date dÃĐjà et rien n'indique qu'elle s'inversera. On y constate l'ÃĐvolution du volume de donnÃĐes (en vert) et du nombre moyen de requÊtes (en rouge) pour le chargement des pages web les plus populaires au monde, durant les quatre derniÃĻres annÃĐes.
I-E. La latence tue▲
|
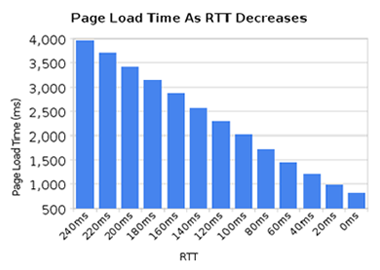
HTTP 1.1 est trÃĻs sensible à la latence, en partie à cause du pipelining HTTP qui demeure problÃĐmatique à un tel point qu'il est dÃĐsactivÃĐ pour la plupart des utilisateurs. |
|
I-F. Head of line blocking▲
Le pipelining HTTP est une maniÃĻre d'envoyer une requÊte additionnelle sans attendre la rÃĐponse de la requÊte prÃĐcÃĐdente. C'est semblable à la file d'attente d'une caisse à la banque ou au supermarchÃĐ. Vous ne savez pas si le client vous prÃĐcÃĐdant est rapide ou s'il s'agit d'une personne qui prendra son temps. Ce phÃĐnomÃĻne dÃĐcrit parfaitement le ÂŦ head of line blocking Âŧ.
|
Bien sÃŧr, vous pouvez faire attention et choisir la file que vous croyez Être la meilleure, et parfois vous pouvez en commencer une nouvelle, mais vous devez prendre une dÃĐcision que vous ne pourrez plus changer par la suite. |
|

Plus de dÃĐtails sur ce sujet peuvent Être consultÃĐs dans l'entrÃĐe 264354 de la base de donnÃĐes Bugzilla de Firefox.